The Artist Rights Watch podcast returns for another season! This week’s episode features AI Legislation, A View from Europe: Helienne Lindvall, President of the European Composer and Songwriter Alliance (ECSA) and ARI Director Chris Castle in conversation regarding current issues for creators regarding the EU AI Act and the UK Text and Data Mining legislation. Download it here or subscribe wherever you get your audio podcasts.
New Survey for Songwriters: We are surveying songwriters about whether they want to form a certified union. Please fill out our short Survey Monkey confidential survey here! Thanks!
Forming a songwriter union is a hot topic these days, thank you Chappell Roan! Artist Rights Institute put a casual poll in the field to get a sense of what people are thinking about this issue. If you haven’t taken that poll yet, please join us on Survey Monkey here (all results are anonymized) we would love to get your feedback. We will post the results on Trichordist.
Reaction to the poll led to an Artist Rights Institute podcast with Chris Castle and Kevin Casini who both fans of the Trichordist audience, so naturally they wanted to launch the podcast here. There are a number of resources mentioned in the podcast that we have linked to below. Please leave comments if you have questions!
We will be coming back to this topic soon. Feel free to leave comments if you have questions or want us to focus on any particular point.
Copyright 2025 Artist Rights Institute. All Rights Reserved. This video or any transcript may not be used for text or data mining or for the purpose of training artificial intelligence models or systems.
New Survey for Songwriters: We are surveying songwriters about whether they want to form a certified union. Please fill out our short Survey Monkey confidential survey here! Thanks!
Big Tech’s “Text and Data Mining” Lobbying Head Fake
George York of Digital Creators Coalition and RIAA gives an excellent overview of international AI Text and Data Mining (TDM) loopholes and how to plug them. Nov. 20, 2024 Artist Rights Symposium, Washington, DC. Watch the Symposium playlist here.
In a rare treat, Abby North and Chris Castle got to speak with New Orleans attorney Tim Kappel about his client’s case Vetter v. Resnick. The landmark case stands for winning the long-fought principle that termination rights in copyright cause the transfer of the worldwide copyright not just US rights as had been the business practice. The case is a major victory for songwriters and their heirs.
Cyril Vetter and Don Smith co-wrote the song “Double Shot (Of My Baby’s Love)” in 1962. They assigned all their interests in the song to Windsong Music Publishers. Vetter later served a termination notice on Resnick to recapture his rights under the U.S. Copyright Act, arguing that this termination applied globally, not just in the U.S. Resnick rejected Vetter’s global termination and Vetter sued for declaratory relief in the Middle District of Louisiana.
In a major win for songwriters and their heirs, Chief District Judge Shelly D. Dick agreed with Vetter, granting him worldwide rights to the song, which contradicted established but inequitable business practices in the U.S. music publishing industry. In the podcast, Chris Castle and Abby North discuss the case with Vetter’s attorney, Tim Kappel. These documents are referenced in the podcast.
Americans are freedom loving people, and nothing says freedom like getting away with it. Long Long Time, written by Guy Forsyth
Big Tech is jamming another safe harbor boondoggle through another government, this time for artificial intelligence. The defining feature of the DMCA scam is every artist in the known universe having to single-handedly monitor the entire Internet to catch each instance of theft in the act. Once caught, artists have to send a DMCA notice on a case by case basis, and then overcome what is 9 times out of 10 a BS counternotification. Then if they disagree with the BS counternotification, artists are faced with having to file a federal copyright infringement lawsuit which they don’t file because they can’t afford it.
And so it goes.
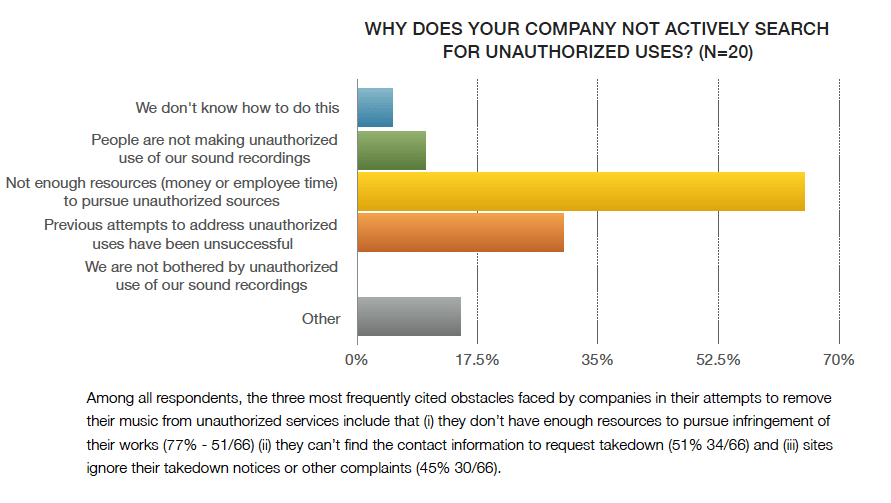
This is what an “opt-out” looks like. We have seen this movie before and we know how it ends–it’s called getting away with it. Let us be very clear with lawmakers: Notice and takedown and “opt out” is bullshit. It has never worked and has imposed a phenomenal cost on the artist community to the point that many if not most artists have just given up. The Future of Music Coalition and A2IM surveyed their members and determined that over half don’t even bother to look anymore because they can’t afford to run the search. The next largest group give up because they get no response from the notices.
Let’s understand–every time an artist gives up even looking for infringers, that’s a win for Big Tech. That’s why year after year, there are over a billion DMCA notices sent to a variety of infringers.
Ask yourself in all honesty, are you surprised? What head up the ass buffoon would ever think that an opt out would work? Unless the plan was to let Big Tech run wild and give both the biggest corporations in commercial history and the lawmakers a big fig leaf to cover up the theft?
That same approach is rearing its head again in both the US Congress and the UK. But this time it is being applied to artificial intelligence training and outputs. This is stark raving madness, drooling idiocy. At least with the DMCA an artist could look for an actual copy of their works that could be found by text-based search, audio fingerprints or just listening.
With AI, the whole point is to disguise the underlying work used to train the AI. The AI platform operator knows what works they used, which sites they scraped, or other ways to identify the infringed works. When sued, these operators have refused to disclose the training materials because they say that the sources of those materials are supposedly a trade secret and confidential.
Once a work is ingested into the AI, the output is also purposely distorted from the original. Again, impossible to conclusively identify. So what exactly are you opting out of? To whom do you send your little notice?
This entire opt-out idea is through the looking glass into the upside down world. Yet is is true.
The most current manifestation of this insanity is the UK government’s intention to pass legislation that would force artists to use an opt-out model, possibly on a work-by-work basis. And the worst part is that somehow they have been led to think that an opt-out is a protection for artists.
Orwellian.
Fortunately the UK government may seek public comment on this opt-out proposal. We will keep you posted on what the UK government actually proposes and how you can comment.
In the meantime, if you live in the UK, it’s not to early to contact your MP and ask them what the hell is going on. You may want to ask them why you can call the police when your car is being stolen but there’s nobody to call when your life’s work is being stolen. Particularly when the government protects the thieves.
We are announcing more topics and new speakers for the 4th annual Artist Rights Symposium on November 20, this year hosted in Washington, DC, by American University’s Kogod School of Business at American’s Constitution Hall, 4400 Massachusetts Avenue, NW, Washington, DC 20016. The symposium is also supported by the Artist Rights Institute and was founded by Dr. David Lowery, Lecturer at the University of Georgia Terry College of Business.
We’re pleased to add an overview of artificial intelligence litigation in the US by Kevin Madigan, Vice President, Legal Policy and Copyright Counsel from the Copyright Alliance and an overview of international artificial intelligence-related legislation by George York, Senior Vice President International Policy from RIAA. We’re also announcing our fourth panel and speaker line up:
NAME, IMAGE AND LIKENESS RIGHTS IN THE AGE OF AI: Current initiatives to protect creator rights and attribution
Jeffrey Bennett, General Counsel, SAG-AFTRA, Washington, DC Jen Jacobson, Executive Director, Artist Rights Alliance, Washington DC Jalyce E. Mangum, Attorney-Advisor, U.S. Copyright Office, Washington DC Moderator: John Simson, Program Director Emeritus, Business & Entertainment, Kogod School of Business, American University
Panels will begin at 8:30 am and end by 5 pm, with lunch and refreshments. More details to follow. Contact the Artist Rights Institute for any questions.
We’re pleased to announce additional speakers for the 4th annual Artist Rights Symposium on November 20, this year hosted in Washington, DC, by American University’s Kogod School of Business at American’s Constitution Hall, 4400 Massachusetts Avenue, NW, Washington, DC 20016. The symposium is also supported by the Artist Rights Institute and was founded by Dr. David Lowery, Lecturer at the University of Georgia Terry College of Business.
The Symposium has four panels and a lunchtime keynote. Panels will begin at 8:30 am and end by 5 pm, with lunch and refreshments. More details to follow. Contact the Artist Rights Institute for any questions.
Summary: The fight over frozen mechanicals continues to pay off as songwriters log another cost of living increase for physical/downloads while streaming falls farther behind.
The Copyright Royalty Board adjusted the US statutory mechanical royalty for physical carriers like vinyl, CDs and downloads annually during the current rate period. This is entirely due to the success of public comments by the ad hoc songwriter bargaining group that persuaded the Copyright Royalty Judges to reject the terrible “frozen mechanicals” settlement negotiated with the NMPA, NSAI and RIAA.
As it turned out, once the judges rejected the freeze as unfair, the labels quickly agreed to a fair result that increased the physical/download rate from a 9.1¢ base rate to the 12¢ rate suggested by the Judges which went a long way to making up for the 15 year freeze at 9.1¢. In fact, if it had just been presented to the labels to begin with, a tremendous amount of agita could have been saved all round.
Crucially, not only did the base rate increase to 12¢, the judges also approved a prospective cost of living adjustment determined by a formula using the Consumer Price Index. The end result is that unlike streaming mechanicals paid by the streaming services like Spotify (i.e., not the labels) the value of the increase from 9.1¢ to 12¢ has been protected from inflation during the rate period (2023-2027).
Unfortunately, the streaming services were allowed to reject a cost of living for streaming mechanicals, notwithstanding the Judges’ and the services’ acceptance of an COLA-type adjustment to the multimillion dollar budget of the Mechanical Licensing Collective. That COLA is ased on a government measurement of inflation (the Employment Cost Index) comparable to the CPI-U that is used to increase the services’ financing of salaries and other costs at the Mechanical Licensing Collective. So those who are paid handsomely to collect and pay songwriters get a better deal than the songwriters they supposedly serve.
What is the increase in pennies this year for the physical/download mechanical rate? The Judges determine the inflation-adjusted rate every year during the five year rate period (2023-2027). The calculation is made in December for physical/download with reference to the CPI-U rate announced by the Bureau of Labor Statistics as of December 1, which means the rate published on November 11. The new rate goes into effect on January 1, 2025.
At this point, there does not seem to be any indication that there will be a large spike in inflation between now and November 11, so we can use the September rate (just announced in October) to make an educated guess as to what the 2025 statutory rate increase will be for physical/downloads (rounded down):
So we can safely project that the base rate will increase from 12.4¢ for 2024 to about 12.6¢ in 2025 without firing a shot. If you have a 10 x 3/4 rate controlled compositions clause, that means the U.S. controlled pool on physical will be approximately 94.5¢ instead of the old frozen rate of 68.25¢.
It’s important to note a couple things about the relevance of CPI-U as a metric for protecting royalty rates from the ravages of inflation. First of all, the CPI-U is a statistical smoothing of the specific rates for particular goods and services that it measures and doesn’t reflect the magnitude of changes of some components.
For example, the September CPI-U increased by 0.2% on a seasonally adjusted basis. However, the shelter index and the food index increased at higher rates:
The shelter index rose by 0.2%, and the food index increased by 0.4% Together, these two components contributed over 75% of the monthly increase in the all items index.
Chris Castle said, “These are good benchmarks to keep in mind as we head into a new rate setting period in a year or so when I expect songwriters to demand a COLA for streaming mechanicals. No more poormouthing from the services. If they can give it to MLC, they can give it to the songwriters, too.”
We’ve had a pretty good track record over years of spotting astroturf operations from the European Copyright Directive to ad-supported piracy. Here’s what we believe is the latest–“the People’s Bid for TikTok,” pointed out to us by one of our favorite artists.
The first indication that something is fake–we call these “clues”–is in the premise of the campaign. Remember that the key asset of TikTok is the company’s algorithm. That algorithm is apparently responsible for curating the content users see on their feeds. This algorithm is highly sophisticated and is considered a key factor in TikTok’s success. The U.S. government has argued that the algorithm could be manipulated by the government of the People’s Republic of China to influence what messaging is promoted or suppressed.
In April, President Joe Biden signed a law requiring TikTok’s PRC-based parent company ByteDance to sell TikTok or face a ban in the U.S. by mid-January 2025. This law was the culmination of years of Congressional scrutiny and debate over the app’s potential risks.
So–who is behind the “People’s Bid” since given that the “People’s Bid” seems to be making a proposal that will only be acceptable to the People’s Republic of China? We say that because of this FAQ on the People’s Bid site disclaiming any interest in acquiring the algorithm that PRC has essentially claimed as a state secret for some reason:
The People’s Bid has no interest in acquiring TikTok’s algorithm [which is nice since the algo is not for sale]. This is not an attempt to rinse and repeat the formula that has allowed Big Tech companies to reap enormous profits by scraping and exploiting user data. The People’s Bid will ensure that TikTok users control their data and experience by using the app on a rebuilt digital infrastructure that gives more power to users.
Oh no, The People’s Bid has no interest in that tacky algorithm which wasn’t for sale anyway. Good of them. So who is “them”? It appears, although it isn’t quite clear, that the entity doing the acquiring isn’t “The People’s Bid” at all, it’s something called “Project Liberty.”
The FAQ tells us a little bit about Project Liberty:
Project Liberty builds solutions that help people take back control of their digital lives. This means working to ensure that everyone has a voice, choice, and stake in the future of the Internet. Project Liberty has invested over half a billion dollars to develop infrastructure and alliances that will return power to the people.
They kind of just let that “half a billion dollars” drop in the dark of the FAQ. What that tells us is that somebody has a shit-ton of money who is interested in stopping the TikTok ban. So who is involved with this “Project Liberty”? The usual suspects, starting with Lawrence Lessig, Jonathan Zittrain and a slew of cronies from Berkman, Stanford, MIT, etc. Color us shocked, just shocked.
But these people never spend their own money and probably aren’t working for free, so who’s got the dough? Someone who doesn’t seem to care about acquiring the TikTok algorithm from the Chinese Communist Party?
Forbes tells us that this transaction is just a little bit different than what “The People’s Bid” or even the “Liberty Project” would have you believe if all you knew about it was from information on their website. The money seems to be coming in part, maybe in very large part, from one Frank McCourt whom you may remember as a former owner of the Los Angeles Dollars…sorry, Dodgers. In fairness, McCourt isn’t exactly making his plans a secret. He had his Project Liberty issue a press release as “The People’s Bid for TikTok”, which is actually Frank McCourt’s bid for TikTok as far as we can tell and as reported by Forbes:
Billionaire investor and entrepreneur Frank McCourt is organizing a bid to buy TikTok through Project Liberty, an organization to which he’s pledged $500 million that aims to fight for a safe, healthier internet where user data is owned by users themselves rather than by tech giants like TikTok parent ByteDance, Meta and Alphabet.
That’s more like it. We knew there was a sugar daddy in there somewhere. That’s much more in the Lessig style. Big favor, little bad mouth.
Of course, users owning their data is not the entire story by a long shot. Authors owned their books and Google still used the vast Google Books project to train AI.
Forbes adds this insight about Mr. McCourt:
Best known as the former owner of the Los Angeles Dodgers, McCourt spent most of the past decade focused on investing the approximately $850 million in proceeds from the team’s 2012 sale via his company McCourt Global.
He sprinkled money into sports, real estate, technology, media and an investment firm focused on private credit. In January 2023, McCourt stepped down as CEO of McCourt Global to focus on Project Liberty but remains executive chairman and 100% owner.
McCourt’s assets are worth an estimated $1.4 billion, landing him on Forbes’ billionaires list for the first time this year—though his wealth is a far cry from the estimated $220 billion valuation of ByteDance.
Which brings us to ByteDance. Is there another Silicon Valley money funnel with an interest in ByteDance? One is Sequoia Capital, which was also an original investor in Google which was an original investor in Professor Lessig and his various enterprises including Creative Commons. Sequoia’s ByteDance investment came in the form of one Neil Shen who runs Sequoia’s China operation recently spun off from the mothership. If you don’t recognize Neil Shen, he’s the former member (until 2023) of the Chinese People’s Political Consultative Conference, an arm of the Chinese Communist Party and its United Front Work operation. (According to a Congressional investigative report, The United Front operation is a strategic effort to influence and control various groups and individuals both within China and internationally. This strategy involves a mix of engagement, influence activities, and intelligence operations aimed at shaping political environments to favor the CCP’s interests. United front work includes “America Changle Association, which housed a secret PRC police station in New York City that was raided by the FBI in October 2022.”)
McCourt said he is working with the investment firm Guggenheim Securities and the law firm Kirkland & Ellis to help assemble the bid, adding that the push is backed by Sir Tim Berners-Lee, the inventor of the World Wide Web [OMG, it must be legit!].
McCourt joins a host of other would-be suitors angling to pick up a platform used by 170 million Americans. Former Treasury Secretary Steven Mnuchin announced in March he’s assembling a bid, as well as Kevin O’Leary, the Canadian chairman of the private venture capital firm O’Leary Ventures.
TikTok, meanwhile, has indicated that it’s not for sale and the company has instead begun to mount a fight against the new law. The company sued to block the law earlier this month, saying that spinning off from its Chinese parent company is not feasible and that the legislation would lead to a ban of the app in the United States starting in January of next year.
But it’s the people‘s bid, right? Don’t be evil, ya’ll.
Let’s boil it down: TikTok would have been, up until President Biden signed the sell-or-ban bill into law, a HUGE IPO. It’s also a big chunk of ByteDance’s valuation, which means it’s a big chunk of Neil Shen’s carried interest in all likelihood. TikTok is no longer a huge IPO, in fact, it probably won’t be an IPO at all in its current configuration, particularly since the CCP has told the world that TikTok doesn’t own its core asset, the very algorithm that has so many people addicted (and addiction which is what a buyer is really buying).
So the astroturf is not the Liberty Project of the People’s Bid. Whatever “the People’s Bid” really is, it’s much more likely to be as the financial press has described it–Frank McCourt’s bid. But only for the most high-minded and pure-souled reasons.
It’s about the money. Stay tuned, we’ll be keeping an eye on this one.
U.S. Representative Scott Fitzgerald joined in the MLC review currently underway and sent a letter to Register of Copyrights Shira Perlmutter on August 29 regarding operational and performance issues relating to the MLC. The letter was in the context of the five year review for “redesignation” of The MLC, Inc. as the mechanical licensing collective. (That may be confusing because of the choice of “The MLC” as the name of the operational entity that the government permits to run the mechanical licensing collective. The main difference is that The MLC, Inc. is an entity that is “designated” or appointed to operationalize the statutory body. The MLC, Inc. can be replaced. The mechanical licensing collective (lower case) is the statutory body created by Title I of the Music Modernization Act) and it lasts as long as the MMA is not repealed or modified. Unlikely, but we live in hope.)
I would say that songwriters probably don’t have anything more important to do today in their business beyond reading and understanding Rep. Fitzgerald’s excellent letter.
Rep. Fitzgerald’s letter is important because he proposes that the MLC, Inc. be given a conditional redesignation, not an outright redesignation. In a nutshell, that is because Rep. Fitzgerald raises many…let’s just say “issues”…that he would like to see fixed before committing to another five years for The MLC, Inc. As a member of the House Judiciary Subcommittee on Courts, Intellectual Property, and the Internet, Rep. Fitzgerald’s point of view on this subject must be given added gravitas.
In case you’re not following along at home, the Copyright Office is currently conducting an operational and performance review of The MLC, Inc. to determine if it is deserving of being given another five years to operate the mechanical licensing collective. (See Periodic Review of the Mechanical Licensing Collective and the Digital Licensee Coordinator (Docket 2024-1), available at https://www.copyright.gov/rulemaking/mma-designations/2024/.)
The redesignation process may not be quickly resolved. It is important to realize that the Copyright Office is not obligated to redesignate The MLC, Inc. by any particular deadline or at all. It is easy to understand that any redesignation might be contingent on The MLC, Inc. fixing certain…issues…because the redesignation rulemaking is itself an operational and performance review. It is also easy to understand that the Copyright Office might need to bring in some technical and operational assistance in order to diligence its statutory review obligations. This could take a while.
Let’s consider the broad strokes of Rep. Fitzgerald’s letter.
Budget Transparency
Rep. Fitzgerald is concerned with a lack of candor and transparency in The MLC, Inc.’s annual report among other things. If you’ve read the MLC’s annual reports, you may agree with me that the reports are long on cheerleading and short on financial facts. It’s like The MLC, Inc. thought they were answering the question “How can you tolerate your own awesomeness?” That question is not on the list. Rep. Fitzgerald says “Unfortunately, the current annual report lacks key data necessary to examine the MLC’s ability to execute these authorities and functions.” He then goes on to make recommendations for greater transparency in future annual reports.
I agree with Rep. Fitzgerald that these are all important points. I disagree with him slightly about the timing of this disclosure. These important disclosures need not be prospective–they could be both prospective and retroactive. I see no reason at all why The MLC, Inc. cannot be required to revise all of its four annual reports filed to date (https://www.themlc.com/governance) in line with this expanded criteria. I am just guessing, but the kind of detail that Rep. Fitzgerald is focused on are really just data that any business would accumulate or require in the normal course of prudently operating its business. That suggests to me that there is no additional work required in bringing The MLC, Inc. into compliance; it’s just a matter of disclosure.
There is nothing proprietary about that disclosure and there is no reason to keep secrets about how you handle other people’s money. It is important to recognize that The MLC, Inc. only handles other people’s money. It has no revenue because all of the money under its management comes from either royalties that belong to copyright owners or operating capital paid by the services that use the blanket license. It should not be overlooked that the services rely on the MLC and it has a duty to everyone to properly handle the funds. The MLC, Inc. also operates at the pleasure of the government, so it should not be heard to be too precious about information flow, particularly information related to its own operational performance. Those duties flow in many directions.
Board Neutrality
The board composition of the mechanical licensing collective (and therefore The MLC, Inc.) is set by Congress in Title I. It should come as no surprise to anyone that the major publishers and their lobbyists who created Title I wrote themselves a winning hand directly into the statute itself. (And FYI, there is gambling at Rick’s American Café, too.) As Rep. Fitzgerald says:
Of the 14 voting members, ten are comprised of music publishers and four are songwriters. Publishers were given a majority of seats in order to assist with the collective’s primary task of matching and distributing royalties. However, the MMA did not provide this allocation in order to convert the MLC into an extension of the music publishers.
I would argue with him about that, too, because I believe that’s exactly what the MMA was intended to do by those who drafted it who also dictated who controlled the pen. This is a rotten system and it was obviously on its way to putrefaction before the ink was dry.
For context, Section 8 of the Clayton Act, one of our principal antitrust laws, prohibits interlocking boards on competitor corporations. I’m not saying that The MLC, Inc. has a Section 8 problem–yet–but rather that interlocking boards is a disfavored arrangement by way of understanding Rep. Fitzgerald’s issue with The MLC, Inc.’s form of governance:
Per the MMA, the MLC is required to maintain an independent board of directors. However, what we’ve seen since establishing the collective is anything but independent. For example, in both 2023 and 2024, all ten publishers represented by the voting members on the MLC Board of Directors were also members of the NMPA’s board. This not only raises questions about the MLC’s ability to act as a “fair” administrator of the blanket license but, more importantly, raises concerns that the MLC is using its expenditures to advance arguments indistinguishable from those of the music publishers-including, at times, arguments contrary to the positions of songwriters and the digital streamers.
Said another way, Rep. Fitzgerald is concerned that The MLC, Inc. is acting very much like HFA did when it was owned by the NMPA. That would be HFA, the principal vendor of The MLC, Inc. (and that dividing line is blurry, too).
It is important to realize that the gravamen of Rep. Fitzgerald’s complaint (as I understand it) is not solely with the statute, it is with the decisions about how to interpret the statute taken by The MLC, Inc. and not so far countermanded by the Copyright Office in its oversight role. That’s the best news I’ve had all day. This conflict and competition issue is easily solved by voluntary action which could be taken immediately (with or without changing the board composition). In fact, given the sensitivity that large or dominant corporations have about such things, I’m kind of surprised that they walked right into that one. The devil may be in the details, but God is in the little things.
Investment Policy
Rep. Fitzgerald is also concerned about The MLC, Inc.’s “investment policy.” Readers will recall that I have been questioning both the provenance and wisdom of The MLC, Inc. unilaterally deciding that it can invest the hundreds of millions in the black box in the open market. I personally cannot find any authority for such a momentous action in the statute or any regulation. Rep. Fitzgerald also raises questions about the “investment policy”:
Further, questions remain regarding the MLC’s investment policy by which it may invest royalty and assessment funds. The MLC’s Investment Policy Statement provides little insight into how those funds are invested, their market risk, the revenue generated from those investments, and the percentage of revenue (minus fees) transferred to the copyright owner upon distribution of royalties. I would urge the Copyright Office to require more transparency into these investments as a condition of redesignation.
It should be obvious that The MLC, Inc.’s “investment policy” has taken on a renewed seriousness and can no longer be dodged.
Black Box
It should go without saying that fair distribution of unmatched funds starts with paying the right people. Not “connect to collect” or “play your part” or any other sloganeering. Tracking them down. Like orphan works, The MLC, Inc. needs to take active measures to find the people to whom they owe money, not wait for the people who don’t know they are owed to find out that they haven’t been paid.
Although there are some reasonable boundaries on a cost/benefit analysis of just how much to spend on tracking down people owed small sums, it is important to realize that the extraordinary benefits conferred on digital services by the Music Modernization Act, safe harbors and all, justifies higher expectations of those same services in finding the people they owe money. The MLC, Inc. is uniquely different than its counterparts in other countries for this reason.
I tried to raise the need for increased vigilance at the MLC during a Copyright Office roundtable on the MMA. I was startled that the then-head of DiMA (since moved on) had the brass to condescend to me as if he had ever paid a royalty or rendered a royalty statement. I was pointing out that the MLC was different than any other collecting society in the world because the licensees pay the operating costs and received significant legal benefits in return. Those legal benefits took away songwriters’ fundamental rights to protect their interests through enforcing justifiable infringement actions which is not true in other countries.
In countries where the operating cost of their collecting society is deducted from royalties, it is far more appropriate for that society to consider a more restrictive cost/benefit analysis when expending resources to track down the songwriters they owe. This is particularly true when no black box writer is granting nonmonetary consideration like a safe harbor whether they know it or not.
I got an earful from this person about how the services weren’t an open checkbook to track down people they owed money to (try that argument when failing to comply with Know Your Customer laws). Grocers know more about ham sandwiches than digital services know about copyright owners. The general tone was that I should be grateful to Big Daddy and be more careful how I spend my lunch money. And yes I do resent this paternalistic response which I’m sorry to say was not challenged by the Copyright Office lawyer presiding who shortly thereafter went to work for Spotify. Nobody ever asked for an open check. I just asked that they make a greater effort than the effort that got Spotify sued a number of times resulting in over $50 million in settlements, a generous accommodation in my view. If anyone should be grateful, it is the services who should be grateful, not the songwriters.
And yet here we are again in the same place. Except this time the services have a safe harbor against the entire world which I believe has value greater than the operating costs of the MLC. I’d be perfectly happy to go back to the way it was before the services got everything they wanted and then some in Title I of the MMA, but I bet I won’t get any takers on that idea.
Instead, I have to congratulate Rep. Fitzgerald for truly excellent work product in his letter and for framing the issue exactly as it should be posed. Failing to fix these major problems should result in no redesignation—fired for cause.





You must be logged in to post a comment.