When White House AI Czar David Sacks tweets confidently that “there will be no federal bailout for AI” because “five major frontier model companies” will simply replace each other, he is not speaking as a neutral observer. He is speaking as a venture capitalist with overlapping financial ties to the very AI companies now engaged in the most circular investment structure Silicon Valley has engineered since the dot-com bubble—but on a scale measured not in millions or even billions, but in trillions.
Sacks is a PayPal alumnus turned political-tech kingmaker who has positioned himself at the intersection of public policy and private AI investment. His recent stint as a Special Government Employee to the federal government raised eyebrows precisely because of this dual role. Yet he now frames the AI sector as a robust ecosystem that can absorb firm-level failure without systemic consequence.
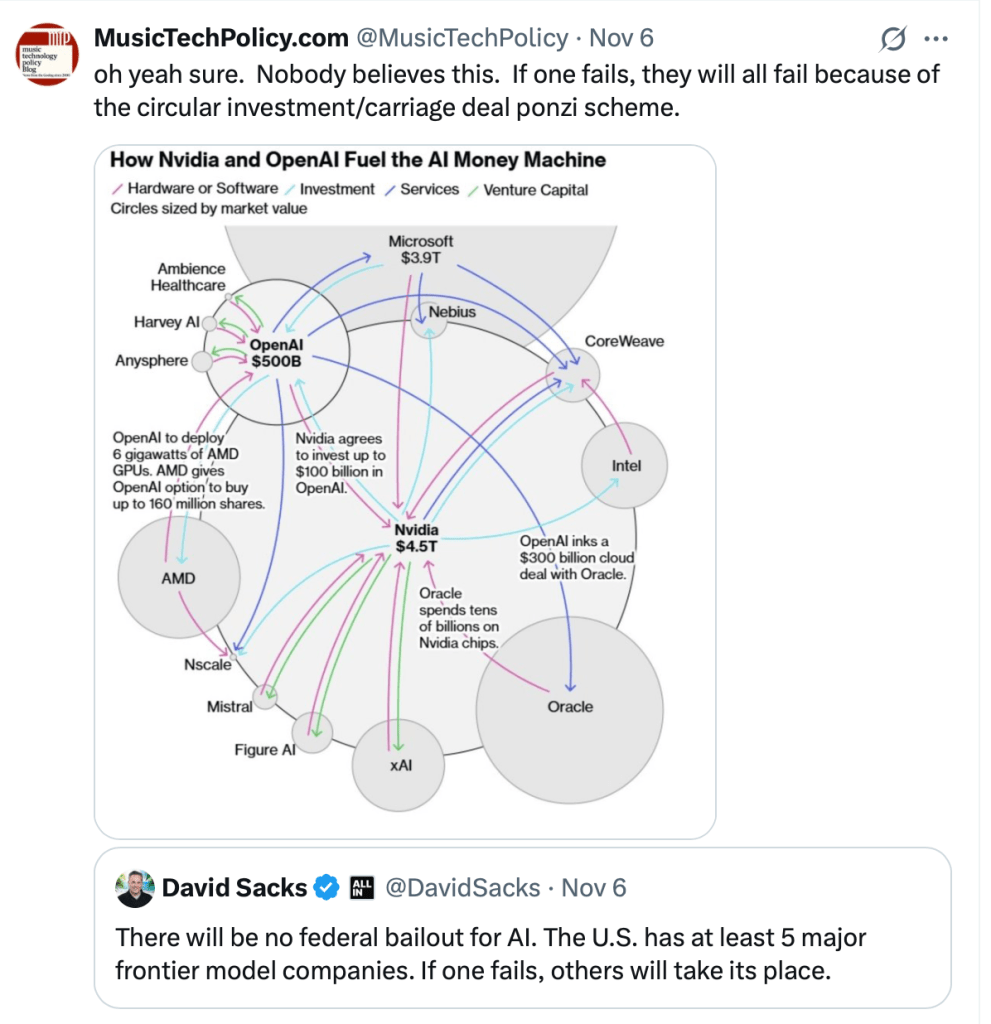
The numbers say otherwise. The diagram circulating in the X-thread exposes the real structure: mutually dependent investments tied together through cross-equity stakes, GPU pre-purchases, cloud-compute lock-ins, and stock-option-backed revenue games. So Microsoft invests in OpenAI; OpenAI pays Microsoft for cloud resources; Microsoft books the revenue and inflates its stake OpenAI. Nvidia invests in OpenAI; OpenAI buys tens of billions in Nvidia chips; Nvidia’s valuation inflates; and that valuation becomes the collateral propping up the entire sector. Oracle buys Nvidia chips; OpenAI signs a $300 billion cloud deal with Oracle; Oracle books the upside. Every player’s “growth” relies on every other player’s spending.
This is not competition. It is a closed liquidity loop. And it’s a repeat of the dot-bomb “carriage” deals that contributed to the stock market crash in 2000.
And underlying all of it is the real endgame: a frantic rush to secure taxpayer-funded backstops—through federal energy deals, subsidized data-center access, CHIPS-style grants, or Department of Energy land leases—to pay for the staggering infrastructure costs required to keep this circularity spinning. The singularity may be speculative, but the push for a public subsidy to sustain it is very real.
Call it what it is: an industry searching for a government-sized safety net while insisting it doesn’t need one.
In the meantime, the circular investing game serves another purpose: it manufactures sky-high paper valuations that can be recycled into legal war chests. Those inflated asset values are now being used to bankroll litigation and lobbying campaigns aimed at rewriting copyright, fair use, and publicity law so that AI firms can keep strip-mining culture without paying for it.
The same feedback loop that props up their stock prices is funding the effort to devalue the work of every writer, musician, actor, and visual artist on the planet—and to lock that extraction in as a permanent feature of the digital economy.
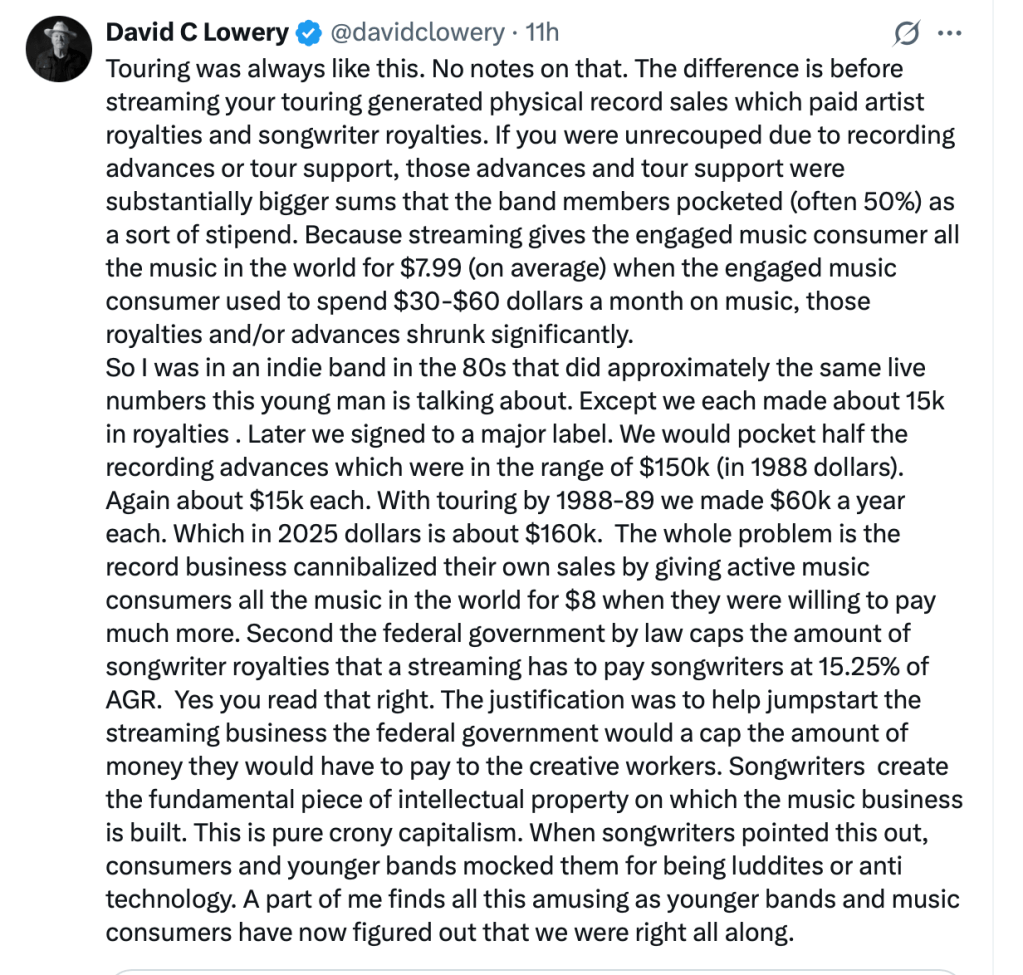
Spotify’s insistence that it’s “misleading” to compare services based on a derived per-stream rate reveals exactly how out of touch the company has become with the very artists whose labor fuels its stock price. Artists experience streaming one play at a time, not as an abstract revenue pool or a complex pro-rata formula. Each stream represents a listener’s decision, a moment of engagement, and a microtransaction of trust. Dismissing the per-stream metric as irrelevant is a rhetorical dodge that shields Spotify from accountability for its own value proposition. (The same applies to all streamers, but Spotify is the only one that denies the reality of the per-stream rate.)
Spotify further claims that users don’t pay per stream but for access as if that negates the artist’s per stream rate payments. It is fallacious to claim that because Spotify users pay a subscription fee for “access,” there is no connection between that payment and any one artist they stream. This argument treats music like a public utility rather than a marketplace of individual works. In reality, users subscribe because of the artists and songs they want to hear; the value of “access” is wholly derived from those choices and the fans that artists drive to the platform. Each stream represents a conscious act of consumption and engagement that justifies compensation.
Economically, the subscription fee is not paid into a vacuum — it forms a revenue pool that Spotify divides among rights holders according to streams. Thus, the distribution of user payments is directly tied to which artists are streamed, even if the payment mechanism is indirect. To say otherwise erases the causal relationship between fan behavior and artist earnings.
The “access” framing serves only to obscure accountability. It allows Spotify to argue that artists are incidental to its product when, in truth, they are the product. Without individual songs, there is nothing to access. The subscription model may bundle listening into a single fee, but it does not sever the fundamental link between listener choice and the artist’s right to be paid fairly for that choice.
Less Than Zero Effect: AI, Infinite Supply and Erasing Artist
In fact, this “access” argument may undermine Spotify’s point entirely. If subscribers pay for access, not individual plays, then there’s an even greater obligation to ensure that subscription revenue is distributed fairly across the artists who generate the listening engagement that keeps fans paying each month. The opacity of this system—where listeners have no idea how their money is allocated—protects Spotify, not artists. If fans understood how little of their monthly fee reached the musicians they actually listen to, they might demand a user-centric payout model or direct licensing alternatives. Or they might be more inclined to use a site like Bandcamp. And Spotify really doesn’t want that.
And to anticipate Spotify’s typical deflection—that low payments are the label’s fault—that’s not correct either. Spotify sets the revenue pool, defines the accounting model, and negotiates the rates. Labels may divide the scraps, but it’s Spotify that decides how small the pie is in the first place either through its distribution deals or exercising pricing power.
Three Proofs of Intention
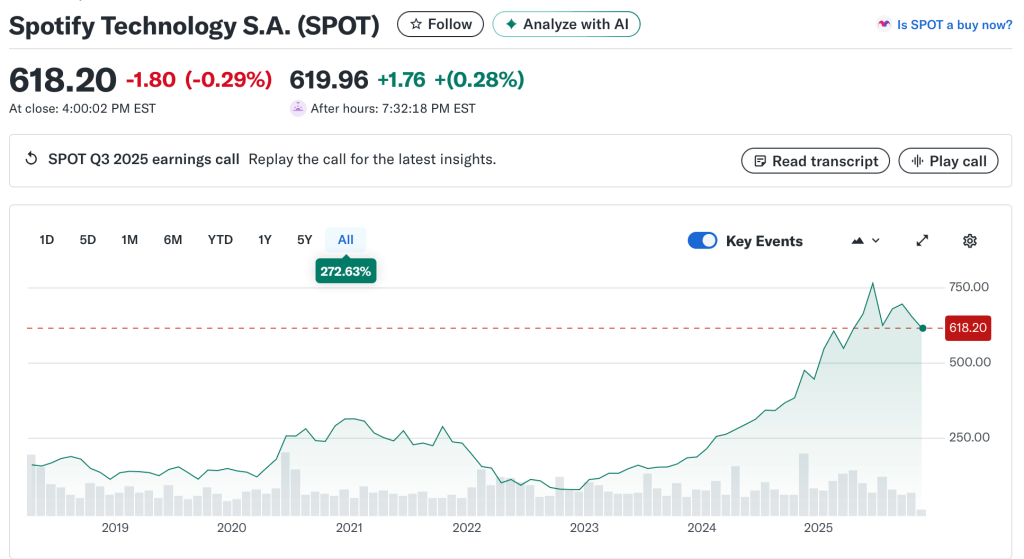
Daniel Ek, the Spotify CEO and arms dealer, made a Dickensian statement that tells you everything you need to know about how Spotify perceives their role as the Streaming Scrooge—“Today, with the cost of creating content being close to zero, people can share an incredible amount of content”.
That statement perfectly illustrates how detached he has become from the lived reality of the people who actually make the music that powers his platform’s market capitalization (which allows him to invest in autonomous weapons). First, music is not generic “content.” It is art, labor, and identity. Reducing it to “content” flattens the creative act into background noise for an algorithmic feed. That’s not rhetoric; it’s a statement of his values. Of course in his defense, “near zero cost” to a billionaire like Ek is not the same as “near zero cost” to any artist. This disharmonious statement shows that Daniel Ek mistakes the harmony of the people for the noise of the marketplace—arming algorithms instead of artists.
Second, the notion that the cost of creating recordings is “close to zero” is absurd. Real artists pay for instruments, studios, producers, engineers, session musicians, mixing, mastering, artwork, promotion, and often the cost of simply surviving long enough to make the next record or write the next song. Even the so-called “bedroom producer” incurs real expenses—gear, software, electricity, distribution, and years of unpaid labor learning the craft. None of that is zero. As I said in the UK Parliament’s Inquiry into the Economics of Streaming, when the day comes that a soloist aspires to having their music included on a Spotify “sleep” playlist, there’s something really wrong here.
Ek’s comment reveals the Silicon Valley mindset that art is a frictionless input for data platforms, not an enterprise of human skill, sacrifice, and emotion. When the CEO of the world’s dominant streaming company trivializes the cost of creation, he’s not describing an economy—he’s erasing one.
While Spotify tries to distract from the “per-stream rate,” it conveniently ignores the reality that whatever it pays “the music industry” or “rights holders” for all the artists signed to one label still must be broken down into actual payments to the individual artists and songwriters who created the work. Labels divide their share among recording artists; publishers do the same for composers and lyricists. If Spotify refuses to engage on per-stream value, what it’s really saying is that it doesn’t want to address the people behind the music—the very creators whose livelihoods depend on those streams. In pretending the per-stream question doesn’t matter, Spotify admits the artist doesn’t matter either.
Less Than Zero or Zeroing Out: Where Do We Go from Here?
The collapse of artist revenue and the rise of AI aren’t coincidences; they’re two gears in the same machine. Streaming’s economics rewards infinite supply at near-zero unit cost which is really the nugget of truth in Daniel Ek’s statements. This is evidenced by Spotify’s dalliances with Epidemic Sound and the like. But—human-created music is finite and costly; AI music is effectively infinite and cheap. For a platform whose margins improve as payout obligations shrink, the logical endgame is obvious: keep the streams, remove the artists.
Two-sided market math. Platforms sell audience attention to advertisers and access to subscribers. Their largest variable cost is royalties. Every substitution of human tracks with synthetic “sound-alikes,” noise, functional audio, or AI mashup reduces royalty liability while keeping listening hours—and revenue—intact. You count the AI streams just long enough to reduce the royalty pool, then you remove them from the system, only to be replace by more AI tracks. Spotify’s security is just good enough to miss the AI tracks for at least one royalty accounting period.
Perpetual content glut as cover. Executives say creation costs are “near zero,” justifying lower per-stream value. That narrative licenses a race to the bottom, then invites AI to flood the catalog so the floor can fall further.
Training to replace, not to pay. Models ingest human catalogs to learn style and voice, then output “good enough” music that competes with the very works that trained them—without the messy line item called “artist compensation.”
Playlist gatekeeping. When discovery is centralized in editorial and algorithmic playlists, platforms can steer demand toward low-or-no-royalty inventory (functional audio, public-domain, in-house/commissioned AI), starving human repertoire while claiming neutrality.
Investor alignment. The story that scales is not “fair pay”; it’s “gross margin expansion.” AI is the lever that turns culture into a fixed cost and artists into externalities.
Where does that leave us? Both streaming and AI “work” best for Big Tech, financially, when the artist is cheap enough to ignore or easy enough to replace. AI doesn’t disrupt that model; it completes it. It also gives cover through a tortured misreading through the “national security” lens so natural for a Lord of War investor like Mr. Ek who will no doubt give fellow Swede and one of the great Lords of War, Alfred Nobel, a run for his money. (Perhaps Mr. Ek will reimagine the Peace Prize.) If we don’t hard-wire licensing, provenance, and payout floors, the platform’s optimal future is music without musicians.
Plato conceived justice as each part performing its proper function in harmony with the whole—a balance of reason, spirit, and appetite within the individual and of classes within the city. Applied to AI synthetic works like those generated by Sora 2, injustice arises when this order collapses: when technology imitates creation without acknowledging the creators whose intellect and labor made it possible. Such systems allow the “appetitive” side—profit and scale—to dominate reason and virtue. In Plato’s terms, an AI trained on human art yet denying its debt to artists enacts the very disorder that defines injustice.
As we’ve been posting about for years—alongside Blake Morgan and the #IRespectMusic movement that you guys have been so good about supporting—there’s still a glaring failure at the heart of U.S. copyright law: performing artists and session musicians receive no royalty for AM/FM radio airplay. Every other developed country (and practically every other country) compensates performers for broadcast use, yet the United States continues to exempt terrestrial radio from paying the people who record the music.
Now Congress is preparing to pass the AM Radio in Every Car Act, a massive government intervention that would literally install the instrument of unfairness into every new car at significant cost to consumers. It’s a breathtaking example of how far the National Association of Broadcasters (NAB) will go to preserve its century-old free ride—by lobbying for public subsidies while refusing to pay artists a penny. This isn’t public service; it’s policy cruelty dressed up as nostalgia.
Hundreds of artists have already spoken out in a letter to Congress demanding fairness through the American Music Fairness Act (AMFA). Their action matters—and yours does too.
👉 Here’s what you can do:
Read the open letter below.
Share it with your representatives.
Tag them on social media with #AMFA and #IRespectMusic.
Don’t let Washington hard-wire injustice into every dashboard. Demand that Congress fix the problem before it funds the next generation of unfairness.
Dear Speaker Johnson, Leader Jeffries, Leader Thune, and Leader Schumer:
Earlier this year, we wrote urging that you take action on the American Music Fairness Act (S.253/H.R.791), legislation that will require that AM/FM radio companies start paying artists for their music. We are grateful for your attention to ensuring America’s recording artists are finally paid for use of our work.
As you may know, some members of Congress are currently seeking to pass legislation that will require every new vehicle manufactured in the United States come pre-installed with AM radio. The passage of the AM Radio for Every Vehicle Act (S.315/H.R.979) would mark another major windfall for the corporate radio industry that makes $13.6 billion each year in advertising revenue while refusing to compensate the performers whose songs play 240 million times each year on AM radio stations. Every year, recording artists lose out on hundreds of millions of dollars in royalties in the U.S. and abroad because of this hundred-year-old loophole.
This is wrong. In the United States of America, every person deserves to be paid for the use of their work. But because of the power held by giant radio corporations in Washington, artists, both big and small, continue to be overlooked, even as every other music delivery platform, including streaming services and satellite radio, pays both the songwriter and performer.
We are asking today that you insist that any legislation that includes the AM Radio for Every Vehicle Act also include the American Music Fairness Act. We do not oppose terrestrial radio. In fact, we appreciate the role that radio has played in our careers and within society, but the 100-year-old argument of promotion that radio continues to hide behind does not ring true in 2025.
When you save the radio industry by mandating its technology remain in cars, we ask that you save the musician too and allow us to be paid fairly when our music is played.
Thank you again for your consideration of this much-needed legislation.
Every few months, an AI company wins a procedural round in court or secures a sympathetic sound bite about “transformative fair use.” Within hours, the headlines declare a new doctrine of spin: the right to train AI on copyrighted works. But let’s be clear — no such right exists and probably never will. That doesn’t mean they won’t keep trying.
A “right to train” is not found anywhere in the Copyright Act or any other law. It’s also not found in court cases on fair-use that the AI lobby leans on. It’s a slogan and it’s spin, not a statute. What we’re watching is a coordinated effort by the major AI labs to manufacture a safe harbor through litigation — using every favorable fair-use ruling to carve out what looks like a precedent for blanket immunity. Then they’ll get one of their shills in Congress or a state legislature to introduce legislation as though a “right to train” was there all along.
How the “Right to Train” Narrative Took Shape
The phrase first appeared in tech-industry briefs and policy papers describing model training as a kind of “machine learning fair use.” The logic goes like this: since humans can read a book and learn from it, a machine should be able to “learn” from the same book without permission.
That analogy collapses under scrutiny. First of all, humans typically bought the book they read or checked it out from a library. Humans don’t make bit-for-bit copies of everything they read, and they don’t reproduce or monetize those copies at global scale. AI training does exactly that — storing expressive works inside model weights, then re-deploying them to generate derivative material.
But the repetitive chant of the term “right to train” serves a purpose: to normalize the idea that AI companies are entitled to scrape, store, and replicate human creativity without consent. Each time a court finds a narrow fair-use defense in a context that doesn’t involve piracy or derivative outputs (because they lose on training on stolen goods like in the Anthropic and Meta cases), the labs and their shills trumpet it as proof that training itself is categorically protected. It isn’t and no court has ever ruled that it is and likely never will.
Fair Use Is Not a Safe Harbor
Fair use is a case-by-case defense to copyright infringement, not a standing permission slip. It weighs purpose, amount, transformation, and market effect — all of which vary depending on the facts. But AI companies are trying to convert that flexible doctrine into a brand new safe harbor: a default assumption that all training is fair use unless proven otherwise. They love a safe harbor in Silicon Valley and routinely abuse them like Section 230, the DMCA and Title I of the Music Modernization Act.
That’s exactly backward. The Copyright Office’s own report makes clear that the legality of training depends on how the data was acquired and what the model does with it. A developer who trains on pirated or paywalled material like Anthropic, Meta and probably all of them to one degree or another, can’t launder infringement through the word “training.”
Even if courts were to recognize limited fair use for truly lawful training, that protection would never extend to datasets built from pirate websites, torrent mirrors, or unlicensed repositories like Sci-Hub, Z-Library, or Common Crawl’s scraped paywalls—more on the scummy Common Crawl another time. The DMCA’s safe harbors don’t protect platforms that knowingly host stolen goods — and neither would any hypothetical “right to train.”
Yet a safe harbor is precisely what the labs are seeking: a doctrine that would retroactively bless mass infringement like Spotify got in the Music Modernization Act and preempt accountability for the sources they used.
And not only do they want a safe harbor — they want it for free. No licenses, no royalties, no dataset audits, no compensation. What do they want? FREE STUFF. When do they want it? NOW! Just blanket immunity, subsidized by every artist, author, and journalist whose work they ingested without consent or payment.
The Real Motive Behind the Push
The reason AI companies need a “right to train” is simple: without it, they have no reliable legal basis for the data that powers their models and they are too cheap to pay and to careless to take the time to license. Most of their “training corpora” were built years before any licenses were contemplated — scraped from the open web, archives, and pirate libraries under the assumption that no one would notice.
This is particularly important for books. Training on books is vital for AI models because books provide structured, high-quality language, complex reasoning, and deep cultural context. They teach models coherence, logic, and creativity that short-form internet text lacks. Without books, AI systems lose depth, nuance, and the ability to understand sustained argument, narrative, and style.
Without books, AI labs have no business. That’s why they steal books. Very simple, really.
Now that creators are suing, the labs are trying to reverse-engineer legitimacy. They want to turn each court ruling that nudges fair use in their direction into a brick in the wall of a judicially-manufactured safe harbor — one that Congress never passed and rights-holders never agreed to and would never agree to.
But safe harbors are meant to protect good-faith intermediaries who act responsibly once notified of infringement. AI labs are not intermediaries; they are direct beneficiaries. Their entire business model depends on retaining the stolen data permanently in model weights that cannot be erased. The “right to train” is not a right — it’s a rhetorical weapon to make theft sound inevitable and a demand from the richest corporations in commercial history for yet another government-sponsored subsidy of infringement by bad actors.
The Myth of the Inevitable Machine
AI’s defenders claim that training on copyrighted works is as natural as human learning. But there’s nothing natural about hoarding other people’s labor at planetary scale and calling it innovation. The truth is simpler: the “right to train” is a marketing term invented to launder unlawful data practices into respectability.
If courts and lawmakers don’t call it what it is — a manufactured, safe harbor for piracy to benefit some of the biggest free riders who ever snarfed down corporate welfare — then history will repeat itself. What Grokster tried to do with distribution, AI is trying to do with cognition: privatize the world’s creative output and claim immunity for the theft.
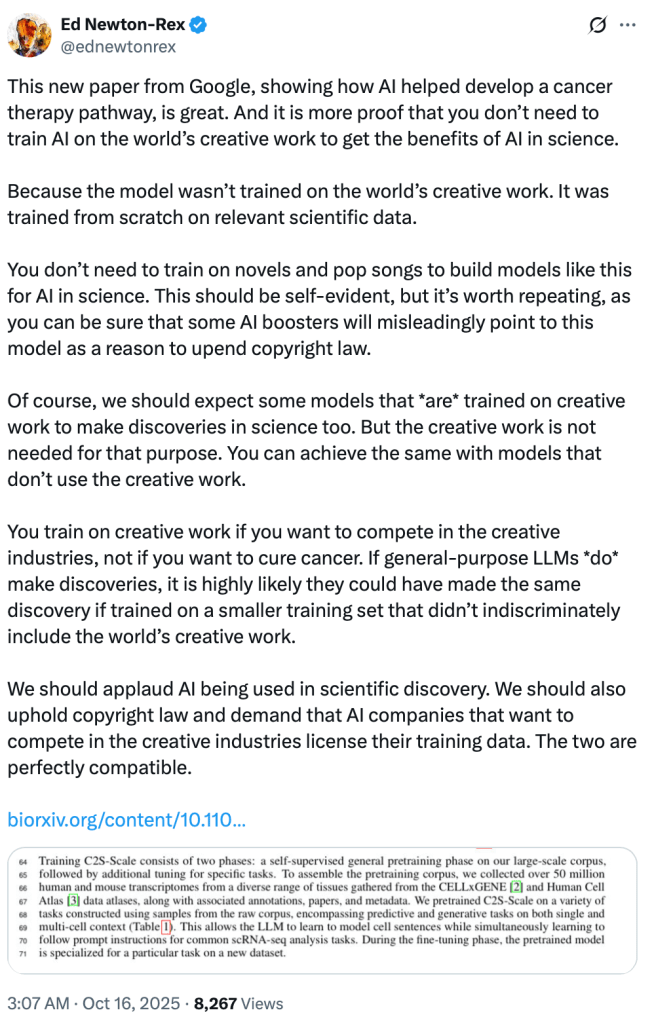
You Don’t Need to Steal Art to Cure Cancer: Why Ed Newton-Rex Is Right About AI and Copyright
Ed Newton-Rex said the quiet truth out loud: you don’t need to scrape the world’s creative works to build AI that saves lives. Or even beat the Chinese Communist Party.
It’s a myth that AI “has to” ingest novels and pop lyrics to learn language. Models acquire syntax, semantics, and pragmatics from any large, diverse corpus of natural language. That includes transcribed speech, forums, technical manuals, government documents, Wikipedia, scientific papers, and licensed conversational data. Speech systems learn from audio–text pairs, not necessarily fiction; text models learn distributional patterns wherever language appears. Of course, literary works can enrich style, but they’re not necessary for competence: instruction tuning, dialogue data, and domain corpora yield fluent models without raiding copyrighted art. In short, creative literature is optional seasoning, not the core ingredient for teaching machines to “speak.”
Google’s new cancer-therapy paper proves the point. Their model wasn’t trained on novels, lyrics, or paintings. It was trained responsibly on scientific data. And yet it achieved real, measurable progress in biomedical research. That simple fact dismantles one of Silicon Valley’s most persistent myths: that copyright is somehow an obstacle to innovation.
You don’t need to train on Joni Mitchell to discover a new gene pathway. You don’t need to ingest John Coltrane to find a drug target. AI used for science can thrive within the guardrails of copyright because science itself already has its own open-data ecosystems—peer-reviewed, licensed, and transparent.
The companies like Anthropic and Meta insisting that “fair use” covers mass ingestion of stolen creative works aren’t curing diseases; they’re training entertainment engines. They’re ripping off artists’ livelihoods to make commercial chatbots, story generators, and synthetic-voice platforms designed to compete against the very creators whose works they exploited. That’s not innovation—it’s market capture through appropriation.
They do it for reasons old as time—they do it for the money.
The ethical divide is clear:
AI for discovery builds on licensed scientific data.
AI for mimicry plunders culture to sell imitation.
We should celebrate the first and regulate the second. Upholding copyright and requiring provenance disclosures doesn’t hinder progress—it restores integrity. The same society that applauds AI in medical breakthroughs can also insist that creative industries remain human-centered and law-abiding. Civil-military fusion doesn’t imply that there’s only two ingredients in the gumbo of life.
If Google can advance cancer research without stealing art, so can everyone else and so can Google keep different rules for the entertainment side of their business or investment portfolio. The choice isn’t between curing cancer and protecting artists—it’s between honesty and opportunism. The repeated whinging of AI labs about “because China” would be a lot more believable if they used their political influence to get the CCP to release Hong Kong activist Jimmy Lai from stir. We can join Jimmy and his amazingly brave son Sebastian and say “because China”, too. #FreeJimmyLai
Universal Music Group’s CEO Sir Lucian Grainge has put the industry on notice in an internal memo to Universal employees: UMG will not license any AI model that uses an artist’s voice—or generates new songs incorporating an artist’s existing songs—without that artist’s consent. This isn’t just a slogan; it’s a licensing policy, an advocacy position, and a deal-making leverage all rolled into one. After the Sora 2 disaster, I have to believe that OpenAI is at the top of the list.
Here’s the memo:
Dear Colleagues,
I am writing today to update you on the progress that we are making on our efforts to take advantage of the developing commercial opportunities presented by Gen AI technology for the benefit of all our artists and songwriters.
I want to address three specific topics:
Responsible Gen AI company and product agreements; How our artists can participate; and What we are doing to encourage responsible AI public policies.
UMG is playing a pioneering role in fostering AI’s enormous potential. While our progress is significant, the speed at which this technology is developing makes it important that you are all continually updated on our efforts and well-versed on the strategy and approach.
The foundation of what we’re doing is the belief that together, we can foster a healthy commercial AI ecosystem in which artists, songwriters, music companies and technology companies can all flourish together.
NEW AGREEMENTS
To explore the varied opportunities and determine the best approaches, we have been working with AI developers to put their ideas to the test. In fact, we were the first company to enter into AI-related agreements with companies ranging from major platforms such as YouTube, TikTok and Meta to emerging entrepreneurs such as BandLab, Soundlabs, and more. Both creatively and commercially our portfolio of AI partnerships continues to expand.
Very recently, Universal Music Japan announced an agreement with KDDI, a leading Japanese telecommunications company, to develop new music experiences for fans and artists using Gen AI. And we are very actively engaged with nearly a dozen different companies on significant new products and service plans that hold promise for a dramatic expansion of the AI music landscape. Further, we’re seeing other related advancements. While just scratching the surface of AI’s enormous potential, Spotify’s recent integration with ChatGPT offers a pathway to move fluidly from query and discovery to enjoyment of music—and all within a monetized ecosystem.
HOW OUR ARTISTS CAN PARTICIPATE
Based on what we’ve done with our AI partners to date, and the new discussions that are underway, we can unequivocally say that AI has the potential to deliver creative tools that will enable us to connect our artists with their fans in new ways—and with advanced capability on a scale we’ve never encountered.
Further, I believe that Agentic AI, which dynamically employs complex reasoning and adaptation, has the potential to revolutionize how fans interact with and discover music.
I know that we will successfully navigate as well as seize these opportunities and that these new products could constitute a significant source of new future revenue for artists and songwriters.
We will be actively engaged in discussing all of these developments with the entire creative community.
While some of the biggest opportunities will require further exploration, we are excited by the compelling AI models we’re seeing emerge.
We will only consider advancing AI products based on models that are trained responsibly. That is why we have entered into agreements with AI developers such as ProRata and KLAY, among others, and are in discussions with numerous additional like-minded companies whose products provide accurate attribution and tools which empower and compensate artists—products that both protect music and enhance its monetization.
And to be clear—and this is very important—we will NOT license any model that uses an artist’s voice or generates new songs which incorporate an artist’s existing songs without their consent.
New AI products will be joined by many other similar ones that will soon be coming to market, and we have established teams throughout UMG that will be working with artists and their representatives to bring these opportunities directly to them.
RESPONSIBLE PUBLIC POLICIES COVERING AI
We remain acutely aware of the fact that large and powerful AI companies are pressuring governments around the world to legitimize the training of AI technology on copyrighted material without owner consent or compensation, among other proposals.
To be clear: all these misguided proposals amount to nothing more than the unauthorized (and, we believe, illegal) exploitation of the rights and property of creative artists.
In addition, we are acting in the marketplace to see our partners embrace responsible and ethical AI policies and we’re proud of the progress being made there. For example, having accurately predicted the rapid rise of AI “slop” on streaming platforms, in 2023 we introduced Artist-Centric principles to combat what is essentially platform pollution. Since then, many of our platform partners have made significant progress in putting in place measures to address the diversion of royalties, infringement and fraud—all to the benefit of the entire music ecosystem.
We commend our partners for taking action to address this urgent issue, consistent with our Artist-Centric approach. Further, we recently announced an agreement with SoundPatrol, a new company led by Stanford scientists that employs patented technology to protect artists’ work from unauthorized use in AI music generators.
We are confident that by displaying our willingness as a community to embrace those commercial AI models which value and enhance human artistry, we are demonstrating that market-based solutions promoting innovation are the answer.
LEADING THE WAY FORWARD
So, as we work to assure safeguards for artists, we will help lead the way forward, which is why we are exploring and finding innovative ways to use this revolutionary technology to create new commercial opportunities for artists and songwriters while simultaneously aiding and protecting human creativity.
I’m very excited about the products we’re seeing and what the future holds. I will update you all further on our progress.
Lucian
Mr. Grainge’s position reframes the conversation from “Can we scrape?” to “How do we get consent and compensate?” That shift matters because AI that clones voices or reconstitutes catalog works is not a neutral utility—it’s a market participant competing with human creators and the rights they rely on.
If everything is “transformative” then nothing is protected—and that guts not just copyright, but artists’ name–image–likeness (NIL), right of publicity and in some jurisdictions, moral rights. A scrape-first, justify-later posture erases ownership, antagonizes creators living and dead, and makes catalogs unpriceable. Why would Universal—or any other rightsholder—partner with a company that treats works and identity as free training fuel? What’s great about Lucian’s statement is he’s putting a flag in the ground: the industry leader will not do business with bad actors, regardless of the consequences.
What This Means in Practice
Consent as the gate. Voice clones and “new songs” derived from existing songs require affirmative artist approval—full stop.
Provenance as the standard. AI firms that want first-party deals must prove lawful ingestion, audited datasets, and enforceable guardrails against impersonation.
Aligned incentives. Where consent exists, there’s room for discovery tools, creator utilities, and new revenue streams; where it doesn’t, there’s no deal.
Watermarks and “AI-generated” labels don’t cure false endorsement, right-of-publicity violations, or market substitution. Platforms that design, market, or profit from celebrity emulation without consent aren’t innovating—they’re externalizing legal and ethical risk onto artists.
Moral Rights: Why This Resonates Globally
Universal’s consent-first stance will resonate in moral-rights jurisdictions where authors and performers hold inalienable rights of attribution and integrity (e.g., France’s droit moral, Germany’s Urheberpersönlichkeitsrecht). AI voice clones and “sound-alike” outputs can misattribute authorship, distort a creator’s artistic identity, or subject their work to derogatory treatment—classic moral-rights harms. Because many countries recognize post-mortem moral rights and performers’ neighboring rights, the “no consent, no license” rule is not just good governance—it’s internationally compatible rights stewardship.
Industry Leadership vs. the “Opt-Out” Mirage
It is absolutely critical that the industry leader actively opposes the absurd “opt-out” gambit and other sleights of hand Big Technocrats are pushing to drive a Mack truck through so-called text-and-data-mining loopholes. Their playbook is simple: legitimize mass training on copyrighted works first, then dare creators to find buried settings or after-the-fact exclusions. That flips property rights on their head and is essentially a retroactive safe harbor,
As Mr. Grainge notes, large AI companies are pressuring governments to bless training on copyrighted material without owner consent or compensation. Those proposals amount to the unauthorized—and unlawful—exploitation of artists’ rights and property. By refusing to play along, Universal isn’t just protecting its catalog; it’s defending the baseline principle that creative labor isn’t scrapable.
Consent or Nothing
Let’s be honest: if AI labs were serious about licensing, we wouldn’t have come one narrow miss away from a U.S. state law AI moratorium triggered by their own overreach. That wasn’t just a safe harbor for copyright infringement, that was a safe harbor for everything from privacy, to consumer protection, to child exploitation, to everything. That’s why it died 99-1 in the Senate, but it was a close run thing,,
And realize, that’s exactly what they want when they are left to their own devices, so to speak. The “opt-out” mirage, the scraping euphemisms, and the rush to codify TDM loopholes all point the same direction—avoid consent and avoid compensation. Universal’s position is the necessary counterweight: consent-first, provenance-audited, revenue-sharing with artists and songwriters (and I would add nonfeatured artists and vocalists) or no deal. Anything less invites regulatory whiplash, a race-to-the-bottom for human creativity, and a permanent breach of trust with artists and their estates.
Reading between the lines, Mr. Grainge has identified AI as both a compelling opportunity and an existential crisis. Let’s see if the others come with him and stare down the bad guys.
The White House has opened a major Request for Information (RFI) on the future of artificial intelligence regulation — and anyone can submit a comment. That means you. This is not just another government exercise. It’s a real opportunity for creators, musicians, songwriters, and artists to make their voices heard in shaping the laws that will govern AI and its impact on culture for decades to come.
Too often, artists find out about these processes after the decisions are already made. This time, we don’t have to be left out. The comment period is open now, and you don’t need to be a lawyer or a lobbyist to participate — you just need to care about the future of your work and your rights. Remember—property rights are innovation, too, just ask Hernando de Soto (Mystery of Capital) or any honest economist.
Here are four key issues in the RFI that matter deeply to artists — and why your voice is critical on each:
1. Transparency and Provenance: Artists Deserve to Know When Their Work Is Used
One of the most important questions in the RFI asks how AI companies should document and disclose the creative works used to train their models. Right now, most platforms hide behind trade secrets and refuse to reveal what they ingested. For artists, that means you might never know if your songs, photographs, or writing were taken without permission — even if they now power billion-dollar AI products.
This RFI is a chance to demand real provenance requirements: records of what was used, when, and how. Without this transparency, artists cannot protect their rights or seek compensation. A strong public record of support for provenance could shape future rules and force platforms into accountability.
2. Derivative Works and AI Memory: Creativity Shouldn’t Be Stolen Twice
The RFI also raises a subtle but crucial issue: even if companies delete unauthorized copies of works from their training sets, the models still retain and exploit those works in their weights and “memory.” This internal use is itself a derivative work — and it should be treated as one under the law.
Artists should urge regulators to clarify that training outputs and model weights built from copyrighted material are not immune from copyright. This is essential to closing a dangerous loophole: without it, platforms can claim to “delete” your work while continuing to profit from its presence inside their AI systems.
3. Meaningful Opt-Out: Creators Must Control How Their Work Is Used
Another critical question is whether creators should have a clear, meaningful opt-out mechanism that prevents their work from being used in AI training or generation without permission. As Artist Rights Institute and many others have demonstrated, “Robots.txt” disclaimers buried in obscure places are not enough. Artists need a legally enforceable system—not another worthless DMCA-style notice and notice and notice and notice and notice and maybe takedown system that platforms must respect and that regulators can audit.
A robust opt-out system would restore agency to creators, giving them the ability to decide if, when, and how their work enters AI pipelines. It would also create pressure on companies to build legitimate licensing systems rather than relying on theft.
4. Anti-Piracy Rule: National Security Is Not a License to Steal
Finally, the RFI invites comment on how national priorities should shape AI development and it’s vital that artists speak clearly here. There must be a bright-line rule that training AI models on pirated content is never excused by national security or “public interest” arguments. This is a real thing—pirate libraries are clearly front and center in AI litigation which have largely turned into piracy cases because the AI lab “national champions” steal books and everything else.
If a private soldier stole a carton of milk from a chow hall, he’d likely lose his security clearance. Yet some AI companies have built entire models on stolen creative works and now argue that government contracts justify their conduct. That logic is backwards. A nation that excuses intellectual property theft in the name of “security” corrodes the rule of law and undermines the very innovation it claims to protect. On top of it, the truth of the case is that the man Zuckerberg is a thief, yet he is invited to dinner at the White House.
A clear anti-piracy rule would ensure that public-private partnerships in AI development follow the same legal and ethical standards we expect of every citizen — and that creators are not forced to subsidize government technology programs with uncompensated labor. Any “AI champion” who steals should lose or be denied a security clearance.
Your Voice Matters — Submit a Comment
The White House needs to hear directly from creators — not just from tech companies and trade associations. Comments from artists, songwriters, and creative professionals will help shape how regulators understand the stakes and set the boundaries.
You don’t need legal training to submit a comment. Speak from your own experience: how unauthorized use affects your work, why transparency matters, what a meaningful opt-out would look like, and why piracy can never be justified by national security.
UK artists including Paul McCartney, Kate Bush and Elton John urged Prime Minister Keir Starmer to protect creators before a UK-US tech pact tied to President Donald Trump’s visit. In a letter, they accuse Labour of blocking transparency rules that would force AI firms to disclose training data and warn proposals enabling training on copyrighted works without permission could let an artist’s life’s work be stolen. Citing human rights documents like the International Covenant on Economic, Social and Cultural Rights, the Berne convention and the European Convention on Human Rights, they frame the issue as a human-rights breach. Peer Beeban Kidron criticised US-heavy working groups. Government says no decision yet and promises a report by March.








You must be logged in to post a comment.