At the center of Vetter v. Resnik are songwriters reclaiming what Congress promised them in a detailed and lengthy legislative negotiation over the 1976 revision to the Copyright Act—a meaningful second chance to terminate what the courts call “unremunerative transfers,” aka crappy deals. That principle comes into sharp focus through Cyril Vetter, whose perseverance brought this case to the Fifth Circuit, and Cyril’s attorney Tim Kappel, whose decades-long advocacy for songwriter rights helped frame the issues not as abstractions, but as lived realities.
Cyril won his case against his publisher at trial in a landmark judicial ruling by Chief Judge Shelly Dick. His publisher appealed Judge Dick’s ruling to the Fifth Circuit. As readers will remember, oral arguments in the case were earlier this year. A bunch of songwriter and author groups including the Artist Rights Institute filed “friend of the court” briefs in the case in favor of Cyril.
In a unanimous opinion, the United States Court of Appeals for the Fifth Circuit affirmed Judge Shelly Dick’s carefully reasoned trial-court ruling, holding that when an author terminates a worldwide grant, the recapture also worldwide. It is not artificially limited to U.S. territory only, which had been the industry practice. The court understood that anything less would hollow out Congress’s intent.
It is often said that the whole point of the termination law is to give authors (including songwriters) a “second bite at the apple”. Which is why the Artist Rights Institute wrote (and was quoted by the 5th Circuit) that limiting the reversion to US rights only is a “second bite at half the apple” which was the opposite of Congressional intent.
What made this 5th Circuit decision especially meaningful for the creative community is that the Fifth Circuit did not reach it in a vacuum. Writing for the panel, Judge Carl Stewart expressly quoted the Artist Rights Institute amicus brief, observing:
“Denying terminating authors the full return of a worldwide grant leaves them with only half of the apple—the opposite of congressional intent.”
That sentence—simple, vivid, and unmistakably human—captured what this case has always been about.
The Artist Rights Institute’s amicus brief did not appear overnight. It grew out of a longstanding relationship between songwriter advocate Tim Kappel and Chris Castle, a collaboration shaped over many years by shared concern for how statutory rights actually function—or fail to function—for creators in the real world.
When the Vetter appeal crystallized the stakes, that history mattered. It allowed ARI to move quickly, confidently, and with credibility—translating dense statutory language into a narrative to help courts understand that termination rights are supposed to restore leverage, not preserve a publisher’s foreign control veto through technicalities.
Crucially, the brief was inspired and strengthened by the voices of songwriter advocates and heirs, including Abby North (heir of composer Alex North), Blake Morgan (godson of songwriter Lesley Gore), and Angela Rose White (heir of legendary music director David Rose) and of course David Lowery and Nikki Rowling. The involvement of these heirs ensured the court understood context—termination is not merely about renegotiating deals for living authors. It is often about families, estates, and heirs—people for whom Congress explicitly preserved termination rights as a matter of intergenerational fairness.
The Fifth Circuit’s opinion reflects that understanding. By rejecting a cramped territorial reading of termination, the court avoided a result that would have undermined heirs’ rights just as surely as authors’ rights.
Vetter v. Resnik represents a rare and welcome alignment: an author willing to press his statutory rights all the way, advocates who understood the lived experience behind those rights, a district judge who took Congress at its word, and an appellate court willing to say plainly that “half of the apple” is not enough.
For the Artist Rights Institute, it was an honor to participate—to stand alongside Cyril Vetter, Tim Kappel, and the community of songwriter advocates and heirs whose experiences shaped a brief that helped the court see the full picture.
And for artists, songwriters, and their families, the decision stands as a reminder that termination rights mean what Congress said they mean—a real chance to reclaim ownership, not an illusion bounded by geography.
There’s a new dance in Washington—it’s called the KowTow
Most musicians don’t spend their days thinking about executive orders. But if you care about your rights, your recordings, your royalties, or your community, or even the environment, you need to understand the Trump Administration’s new executive order on artificial intelligence. The order—presented as “Ensuring a National Policy Framework for AI”—is not a national standard at all. It is a blueprint for stripping states of their power, protecting Big Tech from accountability, and centralizing AI authority in the hands of unelected political operatives and venture capitalists. In other words, it’s business as usual for the special interests led by an unelected bureaucrat, Silicon Valley Viceroy and billionaire investor David Sacks who the New York Times recently called out as a walking conflict of interest.
You’ll Hear “National AI Standard.” That’s Fake News. IT’s Silicon valley’s wild west
Supporters of the EO claim Trump is “setting a national framework for AI.” Read it yourself. You won’t find a single policy on: – AI systems stealing copyrights (already proven in court against Anthropic and Meta) – AI systems inducing self-harm in children – Whether Google can build a water‑burning data center or nuclear plant next to your neighborhood
None of that is addressed. Instead, the EO orders the federal government to sue and bully states like Florida and Texas that pass AI safety laws and threatens to cut off broadband funding unless states abandon their democratically enacted protections. They will call this “preemption” which is when federal law overrides conflicting state laws. When Congress (or sometimes a federal agency) occupies a policy area, states lose the ability to enforce different or stricter rules. There is no federal legislation (EOs don’t count), so there can be no “preemption.”
Who Really Wrote This? The Sacks–Thierer Pipeline
This EO reads like it was drafted directly from the talking points of David Sacks and Adam Thierer, the two loudest voices insisting that states must be prohibited from regulating AI. It sounds that way because it was—Trump himself gave all the credit to David Sacks in his signing ceremony.
– Adam Thierer works at Google’s R Street Institute and pushes “permissionless innovation,” meaning companies should be allowed to harm the public before regulation is allowed. – David Sacks is a billionaire Silicon Valley investor from South Africa with hundreds of AI and crypto investments, documented by The New York Times, and stands to profit from deregulation.
Worse, the EO lards itself with references to federal agencies coordinating with the “Special Advisor for AI and Crypto,” who is—yes—David Sacks. That means DOJ, Commerce, Homeland Security, and multiple federal bodies are effectively instructed to route their AI enforcement posture through a private‑sector financier.
The Trump AI Czar—VICEROY Without Senate Confirmation
Sacks is exactly what we have been warning about for months: the unelected Trump AI Czar
He is not Senate‑confirmed. He is not subject to conflict‑of‑interest vetting. He is a billionaire “special government employee” with vast personal financial stakes in the outcome of AI deregulation.
Under the Constitution, you cannot assign significant executive authority to someone who never faced Senate scrutiny. Yet the EO repeatedly implies exactly that.
Even Trump’s MOST LOYAL MAGA Allies Know This Is Wrong
Trump signed the order in a closed ceremony with sycophants and tech investors—not musicians, not unions, not parents, not safety experts, not even one Red State governor.
Even political allies and activists like Mike Davis and Steve Bannon blasted the EO for gutting state powers and centralizing authority in Washington while failing to protect creators. When Bannon and Davis are warning you the order goes too far, that tells you everything you need to know. Well, almost everything.
And Then There’s Ted Cruz
On top of everything else, the one state official in the room was U.S. Senator Ted Cruz of Texas, a state that has led on AI protections for consumers. Cruz sold out Texas musicians while gutting the Constitution—knowing full well exactly what he was doing as a former Supreme Court clerk.
Why It Matters for Musicians
AI isn’t some abstract “tech issue.” It’s about who controls your work, your rights, your economic future. Right now:
– AI systems train on our recordings without consent or compensation. – Major tech companies use federal power to avoid accountability. – The EO protects Silicon Valley elites, not artists, fans or consumers.
This EO doesn’t protect your music, your rights, or your community. It preempts local protections and hands Big Tech a federal shield.
It’s Not a National Standard — It’s a Power Grab
What’s happening isn’t leadership. It’s *regulatory capture dressed as patriotism*. If musicians, unions, state legislators, and everyday Americans don’t push back, this EO will become a legal weapon used to silence state protections and entrench unaccountable AI power.
What David Sacks and his band of thieves is teaching the world is that he learned from Dot Bomb 1.0—the first time around, they didn’t steal enough. If you’re going to steal, steal all of it. Then the government will protect you.
Every few months, an AI company wins a procedural round in court or secures a sympathetic sound bite about “transformative fair use.” Within hours, the headlines declare a new doctrine of spin: the right to train AI on copyrighted works. But let’s be clear — no such right exists and probably never will. That doesn’t mean they won’t keep trying.
A “right to train” is not found anywhere in the Copyright Act or any other law. It’s also not found in court cases on fair-use that the AI lobby leans on. It’s a slogan and it’s spin, not a statute. What we’re watching is a coordinated effort by the major AI labs to manufacture a safe harbor through litigation — using every favorable fair-use ruling to carve out what looks like a precedent for blanket immunity. Then they’ll get one of their shills in Congress or a state legislature to introduce legislation as though a “right to train” was there all along.
How the “Right to Train” Narrative Took Shape
The phrase first appeared in tech-industry briefs and policy papers describing model training as a kind of “machine learning fair use.” The logic goes like this: since humans can read a book and learn from it, a machine should be able to “learn” from the same book without permission.
That analogy collapses under scrutiny. First of all, humans typically bought the book they read or checked it out from a library. Humans don’t make bit-for-bit copies of everything they read, and they don’t reproduce or monetize those copies at global scale. AI training does exactly that — storing expressive works inside model weights, then re-deploying them to generate derivative material.
But the repetitive chant of the term “right to train” serves a purpose: to normalize the idea that AI companies are entitled to scrape, store, and replicate human creativity without consent. Each time a court finds a narrow fair-use defense in a context that doesn’t involve piracy or derivative outputs (because they lose on training on stolen goods like in the Anthropic and Meta cases), the labs and their shills trumpet it as proof that training itself is categorically protected. It isn’t and no court has ever ruled that it is and likely never will.
Fair Use Is Not a Safe Harbor
Fair use is a case-by-case defense to copyright infringement, not a standing permission slip. It weighs purpose, amount, transformation, and market effect — all of which vary depending on the facts. But AI companies are trying to convert that flexible doctrine into a brand new safe harbor: a default assumption that all training is fair use unless proven otherwise. They love a safe harbor in Silicon Valley and routinely abuse them like Section 230, the DMCA and Title I of the Music Modernization Act.
That’s exactly backward. The Copyright Office’s own report makes clear that the legality of training depends on how the data was acquired and what the model does with it. A developer who trains on pirated or paywalled material like Anthropic, Meta and probably all of them to one degree or another, can’t launder infringement through the word “training.”
Even if courts were to recognize limited fair use for truly lawful training, that protection would never extend to datasets built from pirate websites, torrent mirrors, or unlicensed repositories like Sci-Hub, Z-Library, or Common Crawl’s scraped paywalls—more on the scummy Common Crawl another time. The DMCA’s safe harbors don’t protect platforms that knowingly host stolen goods — and neither would any hypothetical “right to train.”
Yet a safe harbor is precisely what the labs are seeking: a doctrine that would retroactively bless mass infringement like Spotify got in the Music Modernization Act and preempt accountability for the sources they used.
And not only do they want a safe harbor — they want it for free. No licenses, no royalties, no dataset audits, no compensation. What do they want? FREE STUFF. When do they want it? NOW! Just blanket immunity, subsidized by every artist, author, and journalist whose work they ingested without consent or payment.
The Real Motive Behind the Push
The reason AI companies need a “right to train” is simple: without it, they have no reliable legal basis for the data that powers their models and they are too cheap to pay and to careless to take the time to license. Most of their “training corpora” were built years before any licenses were contemplated — scraped from the open web, archives, and pirate libraries under the assumption that no one would notice.
This is particularly important for books. Training on books is vital for AI models because books provide structured, high-quality language, complex reasoning, and deep cultural context. They teach models coherence, logic, and creativity that short-form internet text lacks. Without books, AI systems lose depth, nuance, and the ability to understand sustained argument, narrative, and style.
Without books, AI labs have no business. That’s why they steal books. Very simple, really.
Now that creators are suing, the labs are trying to reverse-engineer legitimacy. They want to turn each court ruling that nudges fair use in their direction into a brick in the wall of a judicially-manufactured safe harbor — one that Congress never passed and rights-holders never agreed to and would never agree to.
But safe harbors are meant to protect good-faith intermediaries who act responsibly once notified of infringement. AI labs are not intermediaries; they are direct beneficiaries. Their entire business model depends on retaining the stolen data permanently in model weights that cannot be erased. The “right to train” is not a right — it’s a rhetorical weapon to make theft sound inevitable and a demand from the richest corporations in commercial history for yet another government-sponsored subsidy of infringement by bad actors.
The Myth of the Inevitable Machine
AI’s defenders claim that training on copyrighted works is as natural as human learning. But there’s nothing natural about hoarding other people’s labor at planetary scale and calling it innovation. The truth is simpler: the “right to train” is a marketing term invented to launder unlawful data practices into respectability.
If courts and lawmakers don’t call it what it is — a manufactured, safe harbor for piracy to benefit some of the biggest free riders who ever snarfed down corporate welfare — then history will repeat itself. What Grokster tried to do with distribution, AI is trying to do with cognition: privatize the world’s creative output and claim immunity for the theft.
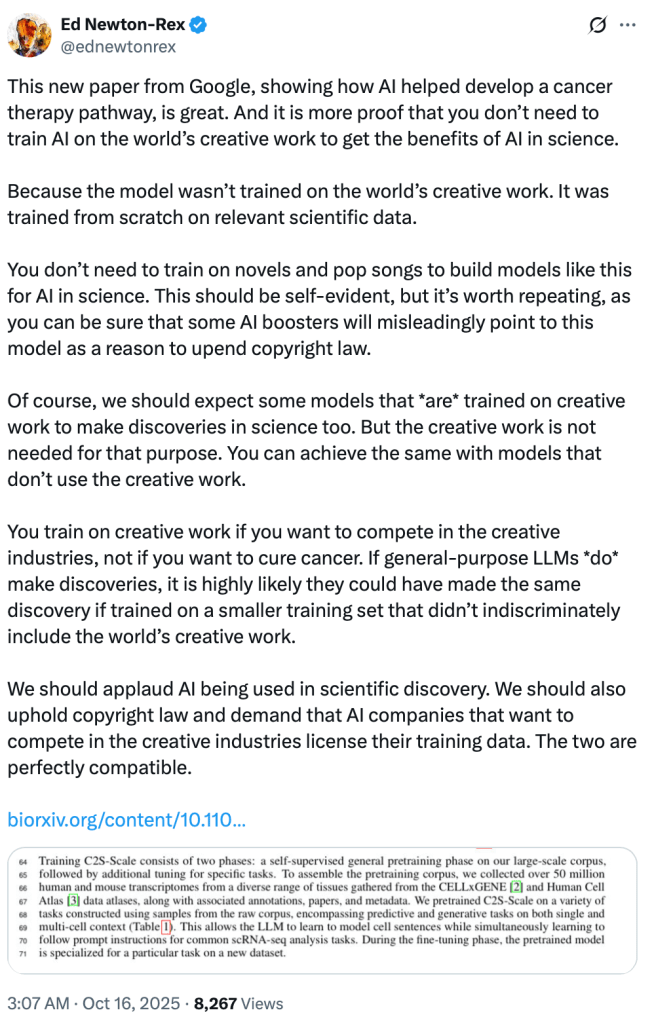
You Don’t Need to Steal Art to Cure Cancer: Why Ed Newton-Rex Is Right About AI and Copyright
Ed Newton-Rex said the quiet truth out loud: you don’t need to scrape the world’s creative works to build AI that saves lives. Or even beat the Chinese Communist Party.
It’s a myth that AI “has to” ingest novels and pop lyrics to learn language. Models acquire syntax, semantics, and pragmatics from any large, diverse corpus of natural language. That includes transcribed speech, forums, technical manuals, government documents, Wikipedia, scientific papers, and licensed conversational data. Speech systems learn from audio–text pairs, not necessarily fiction; text models learn distributional patterns wherever language appears. Of course, literary works can enrich style, but they’re not necessary for competence: instruction tuning, dialogue data, and domain corpora yield fluent models without raiding copyrighted art. In short, creative literature is optional seasoning, not the core ingredient for teaching machines to “speak.”
Google’s new cancer-therapy paper proves the point. Their model wasn’t trained on novels, lyrics, or paintings. It was trained responsibly on scientific data. And yet it achieved real, measurable progress in biomedical research. That simple fact dismantles one of Silicon Valley’s most persistent myths: that copyright is somehow an obstacle to innovation.
You don’t need to train on Joni Mitchell to discover a new gene pathway. You don’t need to ingest John Coltrane to find a drug target. AI used for science can thrive within the guardrails of copyright because science itself already has its own open-data ecosystems—peer-reviewed, licensed, and transparent.
The companies like Anthropic and Meta insisting that “fair use” covers mass ingestion of stolen creative works aren’t curing diseases; they’re training entertainment engines. They’re ripping off artists’ livelihoods to make commercial chatbots, story generators, and synthetic-voice platforms designed to compete against the very creators whose works they exploited. That’s not innovation—it’s market capture through appropriation.
They do it for reasons old as time—they do it for the money.
The ethical divide is clear:
AI for discovery builds on licensed scientific data.
AI for mimicry plunders culture to sell imitation.
We should celebrate the first and regulate the second. Upholding copyright and requiring provenance disclosures doesn’t hinder progress—it restores integrity. The same society that applauds AI in medical breakthroughs can also insist that creative industries remain human-centered and law-abiding. Civil-military fusion doesn’t imply that there’s only two ingredients in the gumbo of life.
If Google can advance cancer research without stealing art, so can everyone else and so can Google keep different rules for the entertainment side of their business or investment portfolio. The choice isn’t between curing cancer and protecting artists—it’s between honesty and opportunism. The repeated whinging of AI labs about “because China” would be a lot more believable if they used their political influence to get the CCP to release Hong Kong activist Jimmy Lai from stir. We can join Jimmy and his amazingly brave son Sebastian and say “because China”, too. #FreeJimmyLai
Universal Music Group’s CEO Sir Lucian Grainge has put the industry on notice in an internal memo to Universal employees: UMG will not license any AI model that uses an artist’s voice—or generates new songs incorporating an artist’s existing songs—without that artist’s consent. This isn’t just a slogan; it’s a licensing policy, an advocacy position, and a deal-making leverage all rolled into one. After the Sora 2 disaster, I have to believe that OpenAI is at the top of the list.
Here’s the memo:
Dear Colleagues,
I am writing today to update you on the progress that we are making on our efforts to take advantage of the developing commercial opportunities presented by Gen AI technology for the benefit of all our artists and songwriters.
I want to address three specific topics:
Responsible Gen AI company and product agreements; How our artists can participate; and What we are doing to encourage responsible AI public policies.
UMG is playing a pioneering role in fostering AI’s enormous potential. While our progress is significant, the speed at which this technology is developing makes it important that you are all continually updated on our efforts and well-versed on the strategy and approach.
The foundation of what we’re doing is the belief that together, we can foster a healthy commercial AI ecosystem in which artists, songwriters, music companies and technology companies can all flourish together.
NEW AGREEMENTS
To explore the varied opportunities and determine the best approaches, we have been working with AI developers to put their ideas to the test. In fact, we were the first company to enter into AI-related agreements with companies ranging from major platforms such as YouTube, TikTok and Meta to emerging entrepreneurs such as BandLab, Soundlabs, and more. Both creatively and commercially our portfolio of AI partnerships continues to expand.
Very recently, Universal Music Japan announced an agreement with KDDI, a leading Japanese telecommunications company, to develop new music experiences for fans and artists using Gen AI. And we are very actively engaged with nearly a dozen different companies on significant new products and service plans that hold promise for a dramatic expansion of the AI music landscape. Further, we’re seeing other related advancements. While just scratching the surface of AI’s enormous potential, Spotify’s recent integration with ChatGPT offers a pathway to move fluidly from query and discovery to enjoyment of music—and all within a monetized ecosystem.
HOW OUR ARTISTS CAN PARTICIPATE
Based on what we’ve done with our AI partners to date, and the new discussions that are underway, we can unequivocally say that AI has the potential to deliver creative tools that will enable us to connect our artists with their fans in new ways—and with advanced capability on a scale we’ve never encountered.
Further, I believe that Agentic AI, which dynamically employs complex reasoning and adaptation, has the potential to revolutionize how fans interact with and discover music.
I know that we will successfully navigate as well as seize these opportunities and that these new products could constitute a significant source of new future revenue for artists and songwriters.
We will be actively engaged in discussing all of these developments with the entire creative community.
While some of the biggest opportunities will require further exploration, we are excited by the compelling AI models we’re seeing emerge.
We will only consider advancing AI products based on models that are trained responsibly. That is why we have entered into agreements with AI developers such as ProRata and KLAY, among others, and are in discussions with numerous additional like-minded companies whose products provide accurate attribution and tools which empower and compensate artists—products that both protect music and enhance its monetization.
And to be clear—and this is very important—we will NOT license any model that uses an artist’s voice or generates new songs which incorporate an artist’s existing songs without their consent.
New AI products will be joined by many other similar ones that will soon be coming to market, and we have established teams throughout UMG that will be working with artists and their representatives to bring these opportunities directly to them.
RESPONSIBLE PUBLIC POLICIES COVERING AI
We remain acutely aware of the fact that large and powerful AI companies are pressuring governments around the world to legitimize the training of AI technology on copyrighted material without owner consent or compensation, among other proposals.
To be clear: all these misguided proposals amount to nothing more than the unauthorized (and, we believe, illegal) exploitation of the rights and property of creative artists.
In addition, we are acting in the marketplace to see our partners embrace responsible and ethical AI policies and we’re proud of the progress being made there. For example, having accurately predicted the rapid rise of AI “slop” on streaming platforms, in 2023 we introduced Artist-Centric principles to combat what is essentially platform pollution. Since then, many of our platform partners have made significant progress in putting in place measures to address the diversion of royalties, infringement and fraud—all to the benefit of the entire music ecosystem.
We commend our partners for taking action to address this urgent issue, consistent with our Artist-Centric approach. Further, we recently announced an agreement with SoundPatrol, a new company led by Stanford scientists that employs patented technology to protect artists’ work from unauthorized use in AI music generators.
We are confident that by displaying our willingness as a community to embrace those commercial AI models which value and enhance human artistry, we are demonstrating that market-based solutions promoting innovation are the answer.
LEADING THE WAY FORWARD
So, as we work to assure safeguards for artists, we will help lead the way forward, which is why we are exploring and finding innovative ways to use this revolutionary technology to create new commercial opportunities for artists and songwriters while simultaneously aiding and protecting human creativity.
I’m very excited about the products we’re seeing and what the future holds. I will update you all further on our progress.
Lucian
Mr. Grainge’s position reframes the conversation from “Can we scrape?” to “How do we get consent and compensate?” That shift matters because AI that clones voices or reconstitutes catalog works is not a neutral utility—it’s a market participant competing with human creators and the rights they rely on.
If everything is “transformative” then nothing is protected—and that guts not just copyright, but artists’ name–image–likeness (NIL), right of publicity and in some jurisdictions, moral rights. A scrape-first, justify-later posture erases ownership, antagonizes creators living and dead, and makes catalogs unpriceable. Why would Universal—or any other rightsholder—partner with a company that treats works and identity as free training fuel? What’s great about Lucian’s statement is he’s putting a flag in the ground: the industry leader will not do business with bad actors, regardless of the consequences.
What This Means in Practice
Consent as the gate. Voice clones and “new songs” derived from existing songs require affirmative artist approval—full stop.
Provenance as the standard. AI firms that want first-party deals must prove lawful ingestion, audited datasets, and enforceable guardrails against impersonation.
Aligned incentives. Where consent exists, there’s room for discovery tools, creator utilities, and new revenue streams; where it doesn’t, there’s no deal.
Watermarks and “AI-generated” labels don’t cure false endorsement, right-of-publicity violations, or market substitution. Platforms that design, market, or profit from celebrity emulation without consent aren’t innovating—they’re externalizing legal and ethical risk onto artists.
Moral Rights: Why This Resonates Globally
Universal’s consent-first stance will resonate in moral-rights jurisdictions where authors and performers hold inalienable rights of attribution and integrity (e.g., France’s droit moral, Germany’s Urheberpersönlichkeitsrecht). AI voice clones and “sound-alike” outputs can misattribute authorship, distort a creator’s artistic identity, or subject their work to derogatory treatment—classic moral-rights harms. Because many countries recognize post-mortem moral rights and performers’ neighboring rights, the “no consent, no license” rule is not just good governance—it’s internationally compatible rights stewardship.
Industry Leadership vs. the “Opt-Out” Mirage
It is absolutely critical that the industry leader actively opposes the absurd “opt-out” gambit and other sleights of hand Big Technocrats are pushing to drive a Mack truck through so-called text-and-data-mining loopholes. Their playbook is simple: legitimize mass training on copyrighted works first, then dare creators to find buried settings or after-the-fact exclusions. That flips property rights on their head and is essentially a retroactive safe harbor,
As Mr. Grainge notes, large AI companies are pressuring governments to bless training on copyrighted material without owner consent or compensation. Those proposals amount to the unauthorized—and unlawful—exploitation of artists’ rights and property. By refusing to play along, Universal isn’t just protecting its catalog; it’s defending the baseline principle that creative labor isn’t scrapable.
Consent or Nothing
Let’s be honest: if AI labs were serious about licensing, we wouldn’t have come one narrow miss away from a U.S. state law AI moratorium triggered by their own overreach. That wasn’t just a safe harbor for copyright infringement, that was a safe harbor for everything from privacy, to consumer protection, to child exploitation, to everything. That’s why it died 99-1 in the Senate, but it was a close run thing,,
And realize, that’s exactly what they want when they are left to their own devices, so to speak. The “opt-out” mirage, the scraping euphemisms, and the rush to codify TDM loopholes all point the same direction—avoid consent and avoid compensation. Universal’s position is the necessary counterweight: consent-first, provenance-audited, revenue-sharing with artists and songwriters (and I would add nonfeatured artists and vocalists) or no deal. Anything less invites regulatory whiplash, a race-to-the-bottom for human creativity, and a permanent breach of trust with artists and their estates.
Reading between the lines, Mr. Grainge has identified AI as both a compelling opportunity and an existential crisis. Let’s see if the others come with him and stare down the bad guys.
The White House has opened a major Request for Information (RFI) on the future of artificial intelligence regulation — and anyone can submit a comment. That means you. This is not just another government exercise. It’s a real opportunity for creators, musicians, songwriters, and artists to make their voices heard in shaping the laws that will govern AI and its impact on culture for decades to come.
Too often, artists find out about these processes after the decisions are already made. This time, we don’t have to be left out. The comment period is open now, and you don’t need to be a lawyer or a lobbyist to participate — you just need to care about the future of your work and your rights. Remember—property rights are innovation, too, just ask Hernando de Soto (Mystery of Capital) or any honest economist.
Here are four key issues in the RFI that matter deeply to artists — and why your voice is critical on each:
1. Transparency and Provenance: Artists Deserve to Know When Their Work Is Used
One of the most important questions in the RFI asks how AI companies should document and disclose the creative works used to train their models. Right now, most platforms hide behind trade secrets and refuse to reveal what they ingested. For artists, that means you might never know if your songs, photographs, or writing were taken without permission — even if they now power billion-dollar AI products.
This RFI is a chance to demand real provenance requirements: records of what was used, when, and how. Without this transparency, artists cannot protect their rights or seek compensation. A strong public record of support for provenance could shape future rules and force platforms into accountability.
2. Derivative Works and AI Memory: Creativity Shouldn’t Be Stolen Twice
The RFI also raises a subtle but crucial issue: even if companies delete unauthorized copies of works from their training sets, the models still retain and exploit those works in their weights and “memory.” This internal use is itself a derivative work — and it should be treated as one under the law.
Artists should urge regulators to clarify that training outputs and model weights built from copyrighted material are not immune from copyright. This is essential to closing a dangerous loophole: without it, platforms can claim to “delete” your work while continuing to profit from its presence inside their AI systems.
3. Meaningful Opt-Out: Creators Must Control How Their Work Is Used
Another critical question is whether creators should have a clear, meaningful opt-out mechanism that prevents their work from being used in AI training or generation without permission. As Artist Rights Institute and many others have demonstrated, “Robots.txt” disclaimers buried in obscure places are not enough. Artists need a legally enforceable system—not another worthless DMCA-style notice and notice and notice and notice and notice and maybe takedown system that platforms must respect and that regulators can audit.
A robust opt-out system would restore agency to creators, giving them the ability to decide if, when, and how their work enters AI pipelines. It would also create pressure on companies to build legitimate licensing systems rather than relying on theft.
4. Anti-Piracy Rule: National Security Is Not a License to Steal
Finally, the RFI invites comment on how national priorities should shape AI development and it’s vital that artists speak clearly here. There must be a bright-line rule that training AI models on pirated content is never excused by national security or “public interest” arguments. This is a real thing—pirate libraries are clearly front and center in AI litigation which have largely turned into piracy cases because the AI lab “national champions” steal books and everything else.
If a private soldier stole a carton of milk from a chow hall, he’d likely lose his security clearance. Yet some AI companies have built entire models on stolen creative works and now argue that government contracts justify their conduct. That logic is backwards. A nation that excuses intellectual property theft in the name of “security” corrodes the rule of law and undermines the very innovation it claims to protect. On top of it, the truth of the case is that the man Zuckerberg is a thief, yet he is invited to dinner at the White House.
A clear anti-piracy rule would ensure that public-private partnerships in AI development follow the same legal and ethical standards we expect of every citizen — and that creators are not forced to subsidize government technology programs with uncompensated labor. Any “AI champion” who steals should lose or be denied a security clearance.
Your Voice Matters — Submit a Comment
The White House needs to hear directly from creators — not just from tech companies and trade associations. Comments from artists, songwriters, and creative professionals will help shape how regulators understand the stakes and set the boundaries.
You don’t need legal training to submit a comment. Speak from your own experience: how unauthorized use affects your work, why transparency matters, what a meaningful opt-out would look like, and why piracy can never be justified by national security.
I believe Americans should have the ability to defend their human data, and their rights to that data, against the largest copyright theft in the history of the world.
Millions of Americans have spent the past two decades speaking and engaging online. Many of you here today have online profiles and writings and creative productions that you care deeply about. And rightly so. It’s your work. It’s you.
What if I told you that AI models have already been trained on enough copyrighted works to fill the Library of Congress 22 times over? For me, that makes it very simple: We need a legal mechanism that allows Americans to freely defend those creations. I say let’s empower human beings by protecting the very human data they create. Assign property rights to specific forms of data, create legal liability for the companies who use that data and, finally, fully repeal Section 230. Open the courtroom doors. Let the people sue those who take their rights, including those who do it using AI.
Third, we must add sensible guardrails to the emergent AI economy and hold concentrated economic power to account. These giant companies have made no secret of their ambitions to radically reshape our economic life. So, we ought to require transparency and reporting each time they replace a working man with a machine.
And the government should inspect all of these frontier AI systems, so we can better understand what the tech titans plan to build and deploy.
Ultimately, when it comes to guardrails, protecting our children should be our lodestar. You may have seen recently how Meta green-lit its own chatbots to have sensual conversations with children—yes, you heard me right. Meta’s own internal documents permitted lurid conversations that no parent would ever contemplate. And most tragically, ChatGPT recently encouraged a troubled teenager to commit suicide—even providing detailed instructions on how to do it.
We absolutely must require and enforce rigorous technical standards to bar inappropriate or harmful interactions with minors. And we should think seriously about age verification for chatbots and agents. We don’t let kids drive or drink or do a thousand other harmful things. The same standards should apply to AI.
Fourth and finally, while Congress gets its act together to do all of this, we can’t kneecap our state governments from moving first. Some of you may have seen that there was a major effort in Congress to ban states from regulating AI for 10 years—and a whole decade is an eternity when it comes to AI development and deployment. This terrible policy was nearly adopted in the reconciliation bill this summer, and it could have thrown out strong anti-porn and child online safety laws, to name a few. Think about that: conservatives out to destroy the very concept of federalism that they cherish … all in the name of Big Tech. Well, we killed it on the Senate floor. And we ought to make sure that bad idea stays dead.
We’ve faced technological disruption before—and we’ve acted to make technology serve us, the people. Powered flight changed travel forever, but you can’t land a plane on your driveway. Splitting the atom fundamentally changed our view of physics, but nobody expects to run a personal reactor in their basement. The internet completely recast communication and media, but YouTube will still take down your video if you violate a copyright. By the same token, we can—and we should—demand that AI empower Americans, not destroy their rights . . . or their jobs . . . or their lives.
🎙️ Artist Rights Roundtable on AI and Copyright: Coffee with Humans and the Machines
📍 Butler Board Room, Bender Arena, American University, 4400 Massachusetts Ave NW, Washington D.C. 20016 | 🗓️ September 18, 2025 | 🕗 8:00 a.m. – 12:00 noon
Hosted by the Artist Rights Institute & American University’s Kogod School of Business, Entertainment Business Program
🔹 Overview:
Join the Artist Rights Institute (ARI) and Kogod’s Entertainment Business Program for a timely morning roundtable on AI and copyright from the artist’s perspective. We’ll explore how emerging artificial intelligence technologies challenge authorship, licensing, and the creative economy — and what courts, lawmakers, and creators are doing in response.
☕ Coffee served starting at 8:00 a.m. 🧠 Program begins at 8:50 a.m. 🕛 Concludes by 12:00 noon — you’ll be free to have lunch with your clone.
🗂️ Program:
8:00–8:50 a.m. – Registration and Coffee
8:50–9:00 a.m. – Introductory Remarks by Dean David Marchick and ARI Director Chris Castle
9:00–10:00 a.m. – Topic 1: AI Provenance Is the Cornerstone of Legitimate AI Licensing:
Speakers: Dr. Moiya McTier Human Artistry Campaign Ryan Lehnning, Assistant General Counsel, International at SoundExchange The Chatbot Moderator Chris Castle, Artist Rights Institute
10:10–10:30 a.m. – Briefing: Current AI Litigation, Kevin Madigan, Senior Vice President, Policy and Government Affairs, Copyright Alliance
10:30–11:30 a.m. – Topic 2: Ask the AI: Can Integrity and Innovation Survive Without Artist Consent?
Speakers: Erin McAnally, Executive Director, Songwriters of North America Dr. Richard James Burgess, CEO A2IM Dr. David C. Lowery, Terry College of Business, University of Georgia.
Moderator: Linda Bloss Baum, Director Business and Entertainment Program, Kogod School of Business
11:40–12:00 p.m. – Briefing: US and International AI Legislation
Is it at thing or is it disco? Our fave Rick Beato has a cautionary tale in this must watch video: AI can mimic but not truly create art. As generative tools get more prevalent, he urges thoughtful curation, artist-centered policies, and an emphasis on emotionally rich, human-driven creativity–also known as creativity. h/t Your Morning Coffee our favorite podcast.
In a symbolic vote that spoke volumes, the U.S. Senate decisively voted 99–1 to strike the toxic AI safe harbor moratorium from the vote-a-rama for the One Big Beautiful Bill Act (HR 1) according to the AP. Senator Ted Cruz, who had previously actively supported the measure, actually joined the bipartisan chorus in stripping it — an acknowledgment that the proposal had become politically radioactive.
To recap, the AI moratorium would have barred states from regulating artificial intelligence for up to 10 years, tying access to broadband and infrastructure funds to compliance. It triggered an immediate backlash: Republican governors, state attorneys general, parents’ groups, civil liberties organizations, and even independent artists condemned it as a blatant handout to Big Tech with yet another rent-seeking safe harbor.
Marsha Blackburn and Maria Cantwell to the Rescue
Credit where it’s due: Senator Marsha Blackburn (R–TN) was the linchpin in the Senate, working across the aisle with Sen. Maria Cantwell to introduce the amendment that finally killed the provision. Blackburn’s credibility with conservative and tech-wary voters gave other Republicans room to move — and once the tide turned, it became a rout. Her leadership was key to sending the signal to her Republican colleagues–including Senator Cruz–that this wasn’t a hill to die on.
Top Cover from President Trump?
But stripping the moratorium wasn’t just a Senate rebellion. This kind of reversal in must-pass, triple whip legislation doesn’t happen without top cover from the White House, and in all likelihood, Donald Trump himself. The provision was never a “last stand” issue in the art of the deal. Trump can plausibly say he gave industry players like Masayoshi Son, Meta, and Google a shot, but the resistance from the states made it politically untenable. It was frankly a poorly handled provision from the start, and there’s little evidence Trump was ever personally invested in it. He certainly didn’t make any public statements about it at all, which is why I always felt it was such an improbable deal point that it was always intended as a bargaining chip whether the staff knew it or not.
One thing is for damn sure–it ain’t coming back in the House which is another way you know you can stick a fork in it despite the churlish shillery types who are sulking off the pitch.
One final note on the process: it’s unfortunate that the Senate Parliamentarian made such a questionable call when she let the AI moratorium survive the Byrd Bath, despite it being so obviously not germane to reconciliation. The provision never should have made it this far in the first place — but oh well. Fortunately, the Senate stepped in and did what the process should have done from the outset.
Now what?
It ain’t over til it’s over. The battle with Silicon Valley may be over on this issue today, but that’s not to say the war is over. The AI moratorium may reappear, reshaped and rebranded, in future bills. But its defeat in the Senate is important. It proves that state-level resistance can still shape federal tech policy, even when it’s buried in omnibus legislation and wrapped in national security rhetoric.
Cruz’s shift wasn’t a betrayal of party leadership — it was a recognition that even in Washington, federalism still matters. And this time, the states — and our champion Marsha — held the line.




You must be logged in to post a comment.