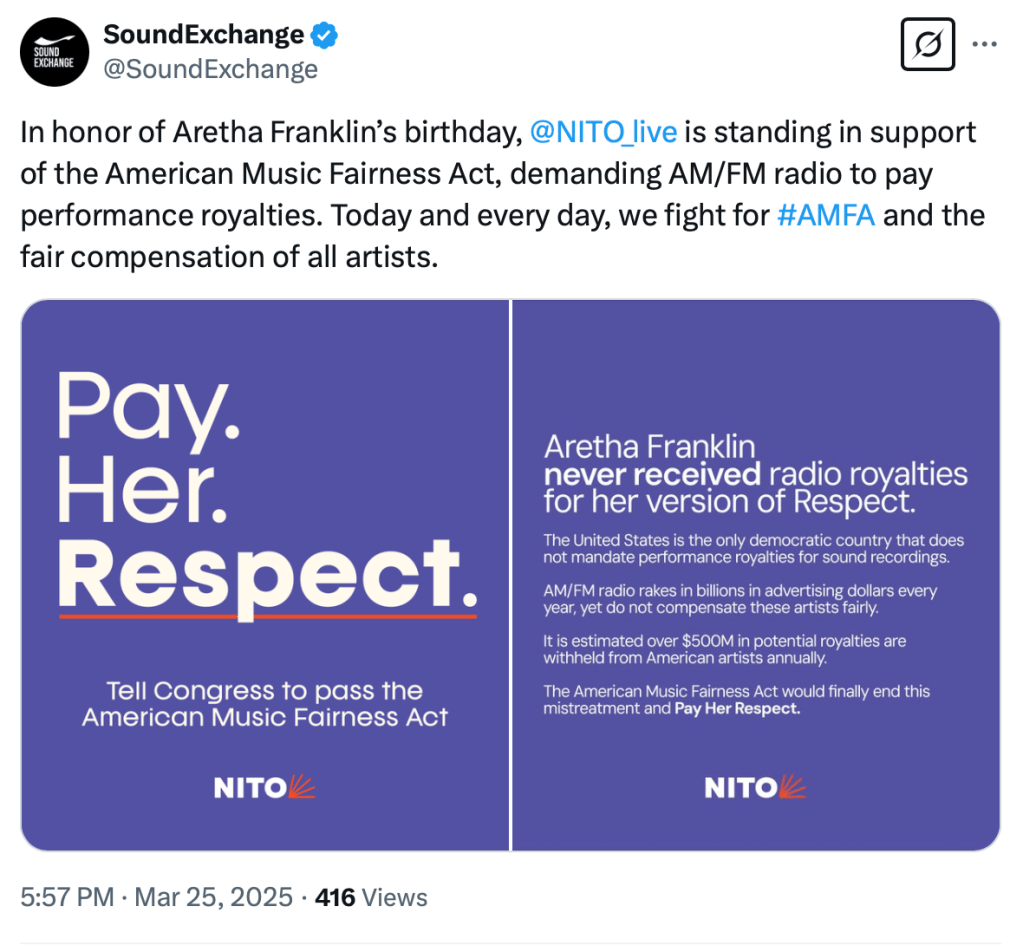
In honor of Aretha Franklin’s birthday, @NITO_live is standing in support of the American Music Fairness Act, demanding AM/FM radio to pay performance royalties. Today and every day, we fight for #AMFA and the fair compensation of all artists. pic.twitter.com/xFHnZjs5gN
We join our friends Blake Morgan, #IRespectMusic, SoundExchange, the National Independent Talent Organization (NITO) and many, many others in asking you to join the fight to support artist pay for radio play by passing the American Music Fairness Act. Find out how you can help here, or find your representative in Congress here.
New Survey for Songwriters: We are surveying songwriters about whether they want to form a certified union. Please fill out our short Survey Monkey confidential survey here! Thanks!
We’ve reported for years about how data centers are a good explanation for why Senators like Ron Wyden seem to always inject themselves into copyright legislation for the sole purpose of slowing it down or killing it, watering it down, or turning it on its head. Why would a senator from Oregon–a state that gave us Courtney Love, Esperanza Spalding, The Decemberists, Sleater-Kinney and the Dandy Warhols–be so such an incredibly basic, no-vibe cosplayer?
Easy answer–he does the bidding of the Big Tech data center operators sucking down that good taxpayer subsidized Oregon hydroelectric power–literally and figuratively. Big Tech loves them some weak copyright and expanded loopholes that let them get away with some hard core damage to artists. Almost as much as they love flexing political muscle.
Senator Wyden with his hand in his own pocket.
This is coming up again in the various public comments on artificial intelligence, which is the data hog of data hogs. For example, the Artist Rights Institute made this point using Oregon as an example in the recent UK Intellectual Property Office call for public comments that produced a huge push back on the plans of UK Prime Minister Sir Kier Starmer to turn Britain into a Google lake for AI, especially the build out of AI data centers.
Google Data Center at The Dalles, Oregon
The thrust of the Oregon discussion in the ARI comment is that Oregon’s experience with data centers should be food for thought in other places (like the UK) as what seems to happen is electricity prices for local rate payers increase while data centers have negotiated taxpayer subsidized discounts. Yes, that old corporate welfare strikes again.
Oregon Taxpayers’ Experience with Crowding Out by Data Centres is a Cautionary Tale for UK
We call the IPO’s attention to the real-world example of the U.S. State of Oregon, a state that is roughly the geographical size of the UK. Google built the first Oregon data centre in The Dalles, Oregon in 2006. Oregon now has 125 of the very data centres that Big Tech will necessarily need to build in the UK to implement AI. In other words, Oregon was sold much the same story that Big Tech is selling you today.
The rapid growth of Oregon data centres driven by the same tech giants like Amazon, Apple, Google, Oracle, and Meta, has significantly increased Oregon’s demand for electricity. This surge in demand has led to higher power costs, which are often passed on to local rate payers while data centre owners receive tax benefits. This increase in price foreshadows the market effect of crowding out local rate payers in the rush for electricity to run AI—demand will only increase and increase substantially as we enter what the International Energy Agency has called “the age of electricity”.[1]
Portland General Electric, a local power operator, has faced increasing criticism for raising rates to accommodate the encroaching electrical power needs of these data centers. Local residents argue that they unfairly bear the increased electrical costs while data centers benefit from tax incentives and other advantages granted by government.[2]
This is particularly galling in that the hydroelectric power in Oregon is largely produced by massive taxpayer-funded hydroelectric and other power projects built long ago.[3] The relatively recent 125 Oregon data centres received significant tax incentives during their construction to be offset by a promise of future jobs. While there were new temporary jobs created during the construction phase of the data centres, there are relatively few permanent jobs required to operate them long term as one would expect from digitized assets owned by AI platforms.
Of course, the UK has approximately 16 times the population of Oregon. Given this disparity, it seems plausible that whatever problems that Oregon has with the concentration of data centers, the UK will have those same problems many times over due to the concentration of populations.
Will AI Produce the Oregon Effect Internationally?
So let’s look at a quick and dirty comparison of the prices that local residents and businesses pay for electricity compared to what data centers in the same states pay. We’re posting this chart because ya’ll love numbers, but mostly to start discussion and research into just how much of an impact all these data centers might have on the supply and demand price setting in a few representative state and countries. But remember this–our experience with Senator Wyden should tell you that all these data centers will give Big Tech even more political clout than they already have.
The chart shows the percentage difference between the residential rate and the data center rate for energy in each state measured. The percentage difference is calculated as: ((Residential Rate – Data Center Rate) ÷ Residential Rate) × 100. When we say “~X% lower” we mean that the data center price per kilowatt hour (¢/kWh) is approximately X% lower than the residential rate, all based on data from Choose Energy or Electricity Plans. We don’t pretend to be energy analysts, so if we got this wrong, someone will let us know.
On a country by country comparison, here’s some more food for thought:
As you can see, most of the G7 countries have significantly higher electricity prices (and therefore potentially higher data prices) than the US and Canada. This suggests that Big Tech data centers will produce the Oregon Effect in those countries with higher residential energy costs in a pre-AI world. That in turn suggests that Big Tech is going to be coming around with their tin cup for corporate welfare to keep their data center electric bills low, or maybe they’ll just buy the electric plants. For themselves.
Either way, it’s unlikely that this data center thumb on the scale and the corporate welfare that goes with it will cause energy prices to decline. And you can just forget that whole Net Zero thing.
If you don’t like where this is going, call your elected representative!
New Survey for Songwriters: We are surveying songwriters about whether they want to form a certified union. Please fill out our short Survey Monkey confidential survey here! Thanks!
Big Tech’s “Text and Data Mining” Lobbying Head Fake
George York of Digital Creators Coalition and RIAA gives an excellent overview of international AI Text and Data Mining (TDM) loopholes and how to plug them. Nov. 20, 2024 Artist Rights Symposium, Washington, DC. Watch the Symposium playlist here.
We will be posting excerpts from the Artist Rights Institute’s comment in the UK’s Intellectual Property Office proceeding on AI and copyright. That proceeding is called a “consultation” where the Office solicits comments from the public (wherever located) about a proposed policy.
In this case it was the UK government’s proposal to require creators to “opt out” of AI data scraping by expanding the law in the UK governing “text and data mining” which is what Silicon Valley wants in a big way. This idea produced an enormous backlash from the creative community that we’ll also be covering in coming weeks as it’s very important that Trichordist readers be up to speed on the latest skulduggery by Big Tech in snarfing down all the world’s culture to train their AI (which has already happened and now has to be undone). For a backgrounder on the “text and data mining” controversy, watch this video by George York of the Digital Creators Coalition speaking at the Artist Rights Institute in DC.
In this section of the comment we offer a simple rule of thumb or policy guideline by which to measure the Government’s rules (which could equally apply in America): Can an artist file a criminal complaint against someone like Sam Altman?
If an artist is more likely to be able to get the police to stop their car from being stolen off the street than to get the police to stop the artist’s life’s work from being stolen online by a heavily capitalized AI platform, the policy will fail
Why Can’t Creators Call 999 [or 911]?
We suggest a very simple policy guideline—if an artist is more likely to be able to get the police to stop their car from being stolen off the street than to get the police to stop the artist’s life’s work from being stolen online by a heavily capitalized AI platform, the policy will fail. Alternatively, if an artist can call the police and file a criminal complaint against a Sam Altman or a Sergei Brin for criminal copyright infringement, now we are getting somewhere.
This requires that there be a clear “red light/green light” instruction that can easily be understood and applied by a beat copper. This may seem harsh, but in our experience with the trillion-dollar market cap club, the only thing that gets their attention is a legal action that affects behavior rather than damages. Our experience suggests that what gets their attention most quickly is either an injunction to stop the madness or prison to punish the wrongdoing.
As a threshold matter, it is clear that AI platforms intend to continue scraping all the world’s culture for their purposes without obtaining consent or notifying rightsholders. It is likely that the bigger platforms already have. For example, we have found our own writings included in CoPilot outputs. Not only did we not consent to that use, but we were also never asked. Moreover, CoPilot’s use of these works clearly violates our terms of service. This level of content scraping is hardly what was contemplated with the “data mining” exceptions.
The Artist Rights Institute filed a comment in the UK Intellectual Property Office’s consultation on Copyright and AI that we drafted. The Trichordist will be posting excerpts from that comment from time to time.
Confounding culture with data to confuse both the public and lawmakers requires a vulpine lust that we haven’t seen since the breathless Dot Bomb assault on both copyright and the public financial markets.
We strongly disagree that all the world’s culture can be squeezed through the keyhole of “data” to be “mined” as a matter of legal definitions. In fact, a recent study by leading European scholars have found that data mining exceptions were never intended to excuse copyright infringement:
Generative AI is transforming creative fields by rapidly producing texts, images, music, and videos. These AI creations often seem as impressive as human-made works but require extensive training on vast amounts of data, much of which are copyright protected. This dependency on copyrighted material has sparked legal debates, as AI training involves “copying” and “reproducing” these works, actions that could potentially infringe on copyrights. In defense, AI proponents in the United States invoke “fair use” under Section 107 of the [US] Copyright Act [a losing argument in the one reported case on point[1]], while in Europe, they cite Article 4(1) of the 2019 DSM Directive, which allows certain uses of copyrighted works for “text and data mining.”
This study challenges the prevailing European legal stance, presenting several arguments:
1. The exception for text and data mining should not apply to generative AI training because the technologies differ fundamentally – one processes semantic information only, while the other also extracts syntactic information.
2. There is no suitable copyright exception or limitation to justify the massive infringements occurring during the training of generative AI. This concerns the copying of protected works during data collection, the full or partial replication inside the AI model, and the reproduction of works from the training data initiated by the end-users of AI systems like ChatGPT….[2]
Moreover, the existing text and data mining exception in European law was never intended to address AI scraping and training:
Axel Voss, a German centre-right member of the European parliament, who played a key role in writing the EU’s 2019 copyright directive, said that law was not conceived to deal with generative AI models: systems that can generate text, images or music with a simple text prompt.[3]
Confounding culture with data to confuse both the public and lawmakers requires a vulpine lust that we haven’t seen since the breathless Dot Bomb assault on both copyright and the public financial markets. This lust for data, control and money will drive lobbyists and Big Tech’s amen corner to seek copyright exceptions under the banner of “innovation.” Any country that appeases AI platforms in the hope of cashing in on tech at the expense of culture will be appeasing their way towards an inevitable race to the bottom. More countries can be predictably expected to offer ever more accommodating terms in the face of Silicon Valley’s army of lobbyists who mean to engage in a lightning strike across the world. The fight for the survival of culture is on. The fight for survival of humanity may literally be the next one up.
We are far beyond any reasonable definition of “text and data mining.” What we can expect is for Big Tech to seek to distract both creators and lawmakers with inapt legal diversions such as trying to pretend that snarfing down all with world’s creations is mere “text and data mining”. The ensuing delay will allow AI platforms to enlarge their training databases, raise more money, and further the AI narrative as they profit from the delay and capital formation.
[1]Thomson-Reuters Enterprise Centre GMBH v. Ross Intelligence, Inc., (Case No. 1:20-cv-00613 U.S.D.C. Del. Feb. 11, 2025) (Memorandum Opinion, Doc. 770 rejecting fair use asserted by defendant AI platform) available at https://storage.courtlistener.com/recap/gov.uscourts.ded.72109/gov.uscourts.ded.72109.770.0.pdf (“[The AI platform]’s use is not transformative because it does not have a ‘further purpose or different character’ from [the copyright owner]’s [citations omitted]…I consider the “likely effect [of the AI platform’s copying]”….The original market is obvious: legal-research platforms. And at least one potential derivative market is also obvious: data to train legal AIs…..Copyrights encourage people to develop things that help society, like [the copyright owner’s] good legal-research tools. Their builders earn the right to be paid accordingly.” Id. at 19-23). See also Kevin Madigan, First of Its Kind Decision Finds AI Training Is Not Fair Use, Copyright Alliance (Feb. 12, 2025) available at https://copyrightalliance.org/ai-training-not-fair-use/ (discussion of AI platform’s landmark loss on fair use defense).
[2] Professor Tim W. Dornis and Professor Sebastian Stober, Copyright Law and Generative AI Training – Technological and Legal Foundations, Recht und Digitalisierung/Digitization and the Law (Dec. 20, 2024)(Abstract) available at https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4946214.
More than 1,000 musicians have come together to release Is This What You Want?, an album protesting the UK government’s proposed changes to copyright law.
In late 2024, the UK government proposed changing copyright law to allow artificial intelligence companies to build their products using other people’s copyrighted work – music, artworks, text, and more – without a licence.
The musicians on this album came together to protest this. The album consists of recordings of empty studios and performance spaces, representing the impact we expect the government’s proposals would have on musicians’ livelihoods.
All profits from the album are being donated to the charity Help Musicians.











You must be logged in to post a comment.