[Professor Tim Wu has a must read post in the New York Times that nails the problems with TikTok (and WeChat). The subtitle are words that will live forever: “Critics say we shouldn’t abandon the ideal of an open internet. But there is such a thing as being a sucker.” Wowsa.]
Were almost any country other than China involved, Mr. Trump’s demands would be indefensible. But the threatened bans on TikTok and WeChat, whatever their motivations, can also be seen as an overdue response, a tit for tat, in a long battle for the soul of the internet.
In China, the foreign equivalents of TikTok and WeChat — video and messaging apps such as YouTube and WhatsApp — have been banned for years. The country’s extensive blocking, censorship and surveillance violate just about every principle of internet openness and decency. China keeps a closed and censorial internet economy at home while its products enjoy full access to open markets abroad.
The asymmetry is unfair and ought no longer be tolerated.
Todays guest opinion is by Trixi a 5 year old female Pit Bull/American Bulldog mix and cancer survivor.
Hi Jeff
You don’t know who I am, but I’m pretty familiar with who you are. You are the guy that sends those men and women up onto my front porch. This happens nearly every day. I’m not sure what it is I ever did to you but it is quite annoying. The newspapers that line the floor around the cat’s litter box (yes, I know I have a problem) also tell me you are the richest man in the world with a net worth of 188 billion dollars. I understand that your company has benefitted enormously from the current pandemic. Those same newspapers report you and your fellow tech titans Zuckerberg and Musk have seen your net worth rise $115 billion just this year. It is a good year to be a tech titan.
In contrast to that the family I live with is largely supported by money earned from performing music. Concert musicians and concert promotion is the family business. Since mid march there has been no concert income for my family. In fact our family income has fallen 80%. Fortunately for me and my family we still receive songwriting royalties from streaming and sales. These royalties are from songs my dog dad wrote over the last 40 years. My understanding is my family uses these royalties as a kind of rainy day fund that helps us get through tough times and the dry periods between albums and tours.
To be clear I’m not whinging here. I have it pretty good for a dog. I spent much of my first few years in kennels having puppies. I know how fortunate I was to be adopted by my family. But back in the spring I developed a dull pain in my left front shoulder. At first I thought it was a muscle injury from trying to scoot under the couch to get what I thought was an old dried up bit of bacon. Long story it wasn’t. It was pretty good. But it wasn’t bacon. Anyway, the pain rapidly worsened until I couldn’t eat or even drink water. I tried to crawl under the house to die. It was that bad. The vet told us I had a malignant bone tumor. I would need my left front leg amputated at the shoulder and a few rounds of chemo. Fortunately the surgery and chemo appear to have been successful. Knock on wood. It took me about a week to figure out how to walk. Now I get around pretty good. Here’s a little secret dogs: It’s easier to run than walk with three legs.
The point is without those songwriter royalties I don’t know if my family would have had the cash to pay for that surgery and treatment. Well maybe that’s not quite true as I’m certain my family would have done anything they could to save me. Put the surgery on credit cards or even taken out a loan. But you get my point. My life is an expense that many music families might not be able to afford.
Now the other day I was in the recycling bin checking to see if all the cans were properly washed out and I came across the full docket for the United States Court of Appeals Washington DC Case No. 19-1028. Fascinating. Basically you, Jeff Bezos, the richest man in the world sued the Copyright Royalty Board to “recalculate” songwriter royalties retroactively 2018-2022. And you won! Now the trade organization that represents you is claiming this is simply a technical detail. But that is not true. it is clear from the actual court filings that you (and your buddies Spotify and Google) want to retroactively reduce songwriter royalties from the current 13.3% downward to around 10.4%. That is, a retroactive 28% pay cut to my family. There is a very real possibility of negative songwriter royalty checks in late 2020 or early 2021. This is during a worldwide financial crisis. When my family has already lost 80% of their income.
So I just have one question for you Jeff.
“How much more fucking money do you need? What kind of asshole sues to retroactively take pay from songwriters during a pandemic?”
Okay that’s two questions. I’m a dog. I’m not good at math. I am good at empathy. You should learn.
Spotify is completely full of shit (as usual). Spotify for Artists webpage the day after they argued in federal court to lower songwriter royalty rates.
Spotify’s claim that they are not suing to lower songwriter royalty rates appears to be a form of False Advertising, that may give them a competitive advantage over competitors. For this reason I filed a complaint with the FTC. Below.
On March 11th 2020 Spotify through its Spotify for Artists webpage made false claims about the nature of its appeal of songwriter royalty rates. (https://artists.spotify.com/blog/you-might-have-heard-about-the-streaming-industry%27s-crb-appeal-here%27s-what ). They also made these claims in a circulated press release on or around March 11th 2020. Specifically, they imply they were not trying to lower songwriter rates. The United States Court of Appeals For the District of Columbia ruling on their appeal (USCA Case #19-1028 Document #1856124 Filed:08/11/2020 Argued 10th of March) clearly indicates this is not the case. Further, Spotify apparently manufactured out of whole cloth the story that their appeal was centered on a technical matter of “bundling” lyric and video rights. On the webpage cited Spotify says “A key area of focus in our appeal will be the fact that the CRB’s decision makes it very difficult for music services to offer ‘bundles’ of music and non-music offerings.” The Appeals Court ruling nor the rest of the docket appear to support this contention. It appears the intention of this statement was to create the false impression that the goal of the appeal was not to lower songwriter rates, thus making consumers think Spotify was not taking a hard line towards songwriter pay. Consumers may have been misled and purchased Spotify subscription over competitors (like Apple) because they thought Spotify was not deeply hostile to pay raise for songwriters (Apple did not appeal songwriter royalties.) Finally, Spotify argued complaint March 10th 2020. The company had to know the March 11th statement was false.
Here is the ruling. Unsealed. I just read it and I’ll tell you this, although it is a technical ruling in many ways, it clearly goes against songwriters. There is little chance this will not lower your royalty rates in the subsequent rehearing.
First, The Court of Appeals all but directs the CRB to put the cap back on “total content costs.” This clearly will have a depressive effect on the alternate mechanical royalty calculation. Second, the court seems to be fundamentally uncomfortable with the fact that songwriters get a (phased in over 5 years) 40% raise. Like everyone involved in the proceedings so far, no one seems to understand the initial rate was arbitrary. It was picked out of thin air when no one knew what streaming meant. Finally it’s totally depressing to see a federal court reiterate the notion that the federal government can not put a streaming service out of business by raising songwriter rates too high. It’s not the governments job to save companies that have bad business models. If the streaming services can’t pay fair rates to songwriters perhaps they should charge their customers more, not pay songwriters less. Why do the federal courts think songwriters have to subsidize the streaming business? All in all a depressing read. The system is broken. Songwriters who every day add value to the GDP of this country are robbed and brutalized by their own government. A distant unaccountable unelected elite that has no concept of our lives. Meanwhile they make Daniel Ek billions of dollars richer every year. Does that seem right to you?
Look! It says so in this blog post! Spotify says it is “supportive” of the 15% effective royalty rate to songwriters but it just wants you to throw in a bunch of other rights for which you are already paid a separate fee. See? That’s cool right? That’s not a pay cut. The appeal of the Copyright Royalty Board rate-setting is actually done to help songwriters!
I mean you can kind of sort of maybe say they are reducing your pay because yes that separate income you get from micro sync and lyric display will be deducted from the 15% effective rate. But no they aren’t trying to lower your mechanical royalty rate, they are just trying to take away other streams of revenue that you already have. I suppose you can say technically they are slashing your pay. While technically correct that would be silly!
I know it’s a little confusing cause by law the Copyright Royalty Board was charged with only setting the streaming mechanical rate in this proceeding. But hey, these are extraordinary times, its okay if the CRB just goes ahead without any constitutional authority and effectively ex-post facto eliminates royalties paid under a different private contract. Sure that’s technically unconstitutional and administrative judges don’t enjoy the same immunity from liability that other judges enjoy, but yeah why not? In times of extraordinary hardship, if streaming services have to wield the awesome power of the federal government to hurt the little guy, so be it. I mean you have to starve a few million peasants to make a crony capitalist omelette right? What’s a 20-30% pay cut to help a billionaires get by?
Billboard has reported that streaming services have won their appeal to force the Copyright Royalty Board to recalculate songwriter streaming royalties for 2018-2022. Yes, that means retroactively calculate 2 1/2 years of royalties. This could easily lead to songwriters getting reduced or negative royalty checks.
Here is how:
In 2017 the royalty rate per stream for songwriters was calculated by dividing 10.4% of gross streaming service revenue by the total number of streams. In 2020 it is calculated using 13.3% of gross streaming service revenue by the total number of streams. If streaming services like YouTube and Spotify get their way that 13.3% will be reduced dramatically. Let’s say streaming services manage to get the Copyright Royalty Board judges to reduce it retroactively to 10.4%. Spotify and YouTube would back out the overpayment from songwriters future royalty checks. Remember Spotify has already done this once when they claimed they overpaid on family subscriptions.
Example: suppose you earned exactly $1000 per quarter over the last 2 1/2 years, or $10,000. Streaming services could contend that they “overpaid” you 28% each quarter. They would be within their rights to back out $2,800 from your next checks. Negative royalty checks. Expect that in late 2020 or early 2021 just when your BMI royalties will shrink from the pandemic induced collapse in local advertising.
Now various industry and trade operatives are trying to spin this ruling as just a technical setback. That the Copyright Royalty Board used a flawed process to calculate songwriter royalty rates. The recalculation is no big deal. They would have you believe that streaming services spent millions of dollars on a federal appeal to get the same rate, to pay songwriters the same amount of money. Does that make any sense to you? Do not be fooled by this exercise in covering their ass. It is unlikely that songwriters rates will remain the same. The purpose of the exercise is to get lower rates and these lower rates will come retroactively out of your checks.
You have to wonder what kind of people work at these streaming services. What kind of person is fully on board with a corporate policy to claw back pay from workers, when those workers have already lost most of their live music income. I urge anyone that knows employees of these three companies (Google, Amazon and Spotify) to publicly out/shame these individuals. Force them to denounce their companies regressive and inhuman policies. Shun them from polite society. Further any artists still cooperating with the digital services like Spotify, Amazon and YouTube should be regarded as strikebreakers and scabs. These artists should be treated accordingly. Artists should pull new releases from streaming services that are pursuing this policy.
As many of you already know the new federal Music Licensing Collective has selected Harry Fox Agency as the vendor to provide song data to the MLC. It is rapidly becoming clear that what this really means is that the MLC will start with the HFA song database and then through a rather convoluted and manual process, songwriters will be required to “ensure the quality of that data” if they expect to get paid. In other words songwriters will do all the heavy lifting.
I’m a little confused here. The MLC received $37 million dollars in startup costs from digital music services. Clearly an accurate database is necessary to start up an entity designed to distribute song royalties. So it should be a start up cost, not an after thought outsourced to songwriters. Especially after we songwriters were told over and over again that the streaming services would pay for MLC.
As an aside, we will never know much about what the MLC spends its money on because the whole fucking budget of the MLC has been redacted on the copyright office website. This is not a joke. How is this even legal? Why the fuck is the budget secret from the songwriters/public it’s supposed to serve? You think the so-called songwriter groups represented on the various boards of the MLC would be the least bit embarrassed by this. Apparently they aren’t.
Figure 1. MLC filing on Copyright Office website. The entire budget is redacted in the public record.
But I digress. That’s another blog. The much bigger problem is the MLC is apparently building the database around the existing HFA database. You know the database that got Spotify and Rhapsody sued. This will be the MLC database. Garbage in Garbage out. This will be an unmitigated disaster. Let me show you:
In 2019 I chose HFA to administer the mechanicals on the self-published part of my catalog. When my team first contacted HFA they were told HFA had information for around 80 of my songs already. Unfortunately the data was wrong. It showed me as 100% writer on many songs that were co-written and co-published. Interesting cause at that point I’d never been paid by HFA. And I am not sure where this information came from as at that point I had never given any splits to HFA. I suspect ass covering because the Spotify/Rhapsody lawsuits involved this part of my catalog (HFA was vendor hired by Spotify to clear songwriter licenses and pay songwriters. They failed and the lawsuits were the result.)
Regardless my team proceeded to update the data and provided the proper splits and co-publishers to HFA. And this is where it gets weird. We received this email from HFA. Here is a snippet.
“For updating songs it is most efficient to process them manually, by entering specific song codes in the “Add/Update Song” section of the eSong tool. Additionally, you cannot relinquish or decrease your splits on songs in our system, as this requires an agent to do it on your behalf. I say this because it appears you have a 100% split on nearly all songs in your catalog. (Emphasis added.)
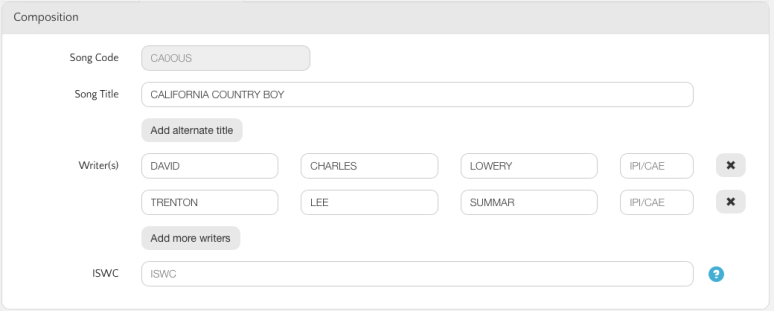
The wording is a little unclear. But I thought that this meant I could “decrease” my share on specific songs, and have the co-writers co-publishers attributed if I went through the manual process. So we sent a list with updated songs splits,ISWC (unique international identifier for a composition) and IPI numbers (unique international identifier for a songwriter or publisher).
I didn’t think any more of this until I had my team build a CWR file. CWR is the most widely used international data format for song information (The MLC is not using this format for some reason). When we created the CWR file we discovered that the HFA publisher data still did not match. Not only that it seemed to be missing important data (ISWC, IPI and ISRC) that we had provided.
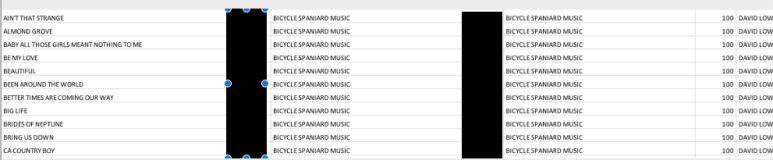
Here is an example song:
Our Data (submitted in 2019 based on BMI records):
Resulting HFA data (2020 public facing database):
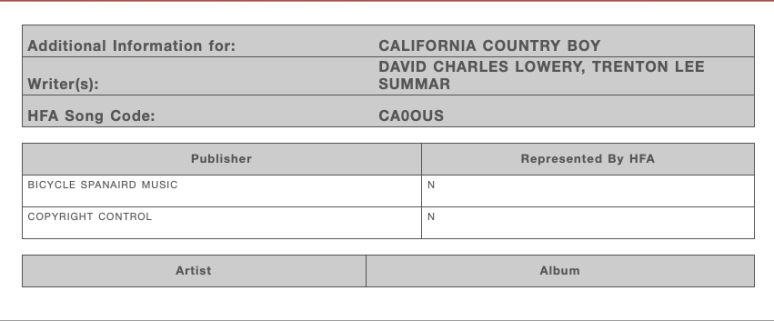
First thing we notice is that HFA is reporting that I am not an HFA registered publisher. WTF? Second problem is that Trent Summar’s publishing share (Farm Rock Music) is not listed. This has instead been assigned to “copyright control.” It is unclear what that means. It is clear that since this song was previously mis-registered as David Lowery/Bicycle Spanaird 100%, HFA records have been updated. The co-writer has been added, but not the co-publisher. But curiously they somehow have Trent’s middle name. Now I thought perhaps this was just a deficiency in the public facing database. So I double checked by looking up the song from my own HFA account.
Here is the (internal data) that search returned.
No IPI numbers? Well maybe those are hidden for privacy. But no ISWC number? And Farm Rock Music is still not listed as a publisher. That is again listed as copyright control. This is really shoddy work. How is the MLC supposed to distribute royalties based on this data?
I checked an additional 25 co-written songs and the data was fucked on all of them: multiple song codes, incorrect splits, missing co-publisher information, missing ISWC codes, and some songs were just not in the HFA database. Honestly it looks like someone never finished doing the job.
It’s possible that I or someone on my team somehow screwed this up, but it seems unlikely. I have copies of the HFA formatted excel sheets that were submitted and they are correct. If all the self-published songwriters are in the same situation then we are likely talking about millions of songs that have bad data. This is very troubling.
“But my BMI Data is Correct. Why Didn’t MLC Start With That Data?”
Really odd, right? The data the MLC is seeking already exists in a machine readable format at the PROs (BMI, ASCAP, SESAC etc). Why is it that songwriters can’t simply opt in to have their data transmitted to the MLC? Wouldn’t this be the easiest way to correct the MLC database? Instead songwriters are going to have to go through and get HFA to manually update each song. For an average songwriter like myself, even at minimum wage that’s probably several hundred dollars worth of work. And my data is pretty organized!
The sad thing is we were told over and over again that streaming services were supposed to pay for costs of the MLC. Why are songwriters being asked to do all this unnecessary work? Even the MLC’s official title they’ve given to the effort make songwriters clean up their mess is insulting: “Play Your Part™.” They thought it so clever apparently they have trademarked the phrase.
The US Copyright Office should step in and look at whats happening with the MLC database. Something is very wrong with the HFA data.
[The Copyright Office is asking for public comments on best practices for dealing with the black box as part of the “Unclaimed Royalties Study” mandated by the Music Modernization Act. We are posting comments or excerpts from comments that we found interesting. You can find other the posted comments here.
This post is from SoundExchange’s filing. I have to say that I have long been impressed by SoundExchange’s problem-solving abilities and commitment to get artists paid. SoundExchange sets the standard that The MLC will be measured by and should try to live up to. Unfortunately, The MLC’s selection of HFA as their data vendor immediately means The MLC is unlikely to have a functioning much less accurate database by the January deadline. They should really pay attention to SoundExchange’s example.]
Core strategies
Through its experience, SoundExchange has identified and embraced certain core
strategies for administering a blanket license that have had the direct effect of minimizing the incidence of unclaimed royalties. First, a collective must act with a total commitment to transparency and accountability.
Second, to the extent possible, a collective must build systems and practices around standard unique identifiers, which are the best way to manage the huge volume of usage and repertoire data that a collective receives in the digital age.
Third, in building its systems and practices, a collective should rigorously distinguish between repertoire data and usage reporting data, and base the repertoire database on data from authoritative sources, typically rights owners. Fourth, it is essential for a collective administering a statutory license to prioritize education and outreach to those who will receive royalties under the blanket license because the collective represents all payees, not just those who have the sophistication or knowledge to register with the collective in the first place. While no system will ever be perfect, a collective that embraces and implements these core strategies will be best positioned to minimize unclaimed royalties. We address each in more detail below.
A. Commit to transparency and accountability
As a collective, it is critical for SoundExchange to commit to transparency and
accountability. We must be responsive to our stakeholders – the people we pay, who have
entrusted us to collect a critical component of their income. As a baseline, a collective must be governed by those it pays. As a next level, a collective must provide tools to stakeholders that give them transparency into how their royalties are collected and distributed, and a means for providing feedback on the metadata associated with their works.
SoundExchange has adopted a policy and practice of continuous improvement. Most
recently, SoundExchange has rolled out new features in SoundExchange Direct, our online account management portal that allows recording artists and rights owners to navigate their digital performance rights and royalties. SoundExchange Direct allows users to manage multiple SoundExchange accounts and add guest users, update account information including contact and payment or banking information, view payment history and revenue data by top recordings and top services and, most relevant here, upload and manage their repertoire data.
Google’s appeal of its major loss to Oracle on fair use is shaping up to be the most important copyright case of the year, if not the decade. It could set fair use standards for years to come. We’re going to be posting installments from the friend of the court brief that David, Helienne, Blake and The Songwriters Guild filed in the U.S. Supreme Court supporting Oracle in the Google v. Oracle fair use case. This is the last installment. We decided to omit the footnotes for this posting, but you can read the whole brief here.
Moreover, Amici believe that Google’s fair use expansion campaigns are designed to serve as a honeypot for Google’s data scraping business model that feeds its outsized profits from ads. Google likewise seems to promote expansion of the fair use doctrine as way to easily keep more videos on YouTube, while providing material support to its partners that allows them to outlast any songwriter or artist in the game of whack-a-mole under its copyright strike policies. No one is giving creators a shadowy milliondollar fund to defend against the misapplication of fair use.
Amicus Mr. Lowery summed it up in his 2014 testimony to the House Judiciary Committee:
I am not concerned with parody, commentary, criticism, documentary filmmakers, or research. These are legitimate fair use categories. I am concerned with the illegal copy that masquerades as fair use, but is really just a copy. This masquerade trivializes legitimate fair use categories and creates conflict where there need be none.
Scope of Fair Use at 22.
Unfortunately, Google manipulates fair use to extract value by monetizing verbatim copies to the great disadvantage of creators who can little afford to fight back against the multi-national, trillion dollar corporation, and usually do not. Thus, independents
are caught without leverage in cases that rarely get to court.
The end result is that even where its use is “free,” Google’s interests are steadfastly commercial. Accordingly, the Federal Circuit was correct in finding that the nature and purpose of Google’s use was entirely commercial in nature.
III. GOOGLE’S PRIVATE INTERESTS ARE NOT THE PUBLIC INTEREST.
The ultimate question in a fair use analysis is “whether, and how powerfully, a finding of fair use would serve or disserve the objectives of the copyright.” Leval at 1110–1111; see also Harper & Row, 471 U.S. at 546 (noting purpose of copyright is to give creators
“a fair return for their labors”).
Google’s only response to whether its use furthers the public interest—i.e., in promoting an effective system of copyright—is that allowing it to copy verbatim Oracle’s declaring code and structure would be “promoting software innovation.” Such verbatim copying is a “facile use of the scissors.” Folsom v. Marsh, 9 F. Cas. 342, 345 (C.C.D. Mass 1841) (Story, J.).
Yet what is good for Google is not synonymous with what is good for the public—no more than “[w]hat’s good for General Bullmoose is good for the USA.” Johnny Mercer and Gene De Paul, Li’l Abner (1956). In fact, a ruling for Google would be “promoting” software innovation only in that the purported “innovation” would be furthering Google’s private
interest—i.e., using works without permission or a license fee.
This case again appears to be the latest in Google’s long-term strategy to use its market dominance and overwhelming commercial power to continually distort copyright exceptions, thereby artificially depressing the market price of copyrighted works. Google’s proposed outcome would be yet another distortion. Were Google to prevail here, Amici expect Google (and its proxies) to throw its full weight behind such a ruling, far beyond the confines of its text. This case would become another totemic faux license or safe harbor that Google could use as a cudgel against creators and copyright owners.
Left unchecked, eventually the copyright distortions they seek—including in the case at bar—could nullify copyright, particularly for those who cannot afford to fight back or fear retaliation for doing so. Under the Google anti-copyright regime, exceptions would devour the rules of protection in whole, digesting art and culture along with them.
CONCLUSION
Amici respectfully suggest that the Court should consider whether a decision in favor of Google would merely “unleash” yet another weapon for Google’s private benefit, and whether Google’s infringement of Oracle’s declaring code and structure constitutes
“simple piracy” for which the company should most certainly be held accountable.
This Court should affirm the decision of the Federal Circuit below.
Respectfully submitted,
CHARLES J. SANDERS
Counsel of Record
29 KINGS GRANT WAY
BRIARCLIFF, NEW YORK 10510
(914) 366-6642
cjs@csanderslaw.com
CHRISTIAN CASTLE
CHRISTIAN L. CASTLE, ATTORNEYS
9600 GREAT HILLS TRAIL
SUITE 150W
AUSTIN, TEXAS 78759
(512) 420-2200
asst1@christiancastle.com
Counsel for Amici Curiae
Google’s appeal of its major loss to Oracle on fair use is shaping up to be the most important copyright case of the year, if not the decade. It could set fair use standards for years to come. We’re going to be posting installments from the friend of the court brief that David, Helienne, Blake and The Songwriters Guild filed in the U.S. Supreme Court supporting Oracle in the Google v. Oracle fair use case. This is part 5. We decided to omit the footnotes for this posting, but you can read the whole brief here.
Cover Page of Friend of the Court Brief
ARGUMENT
B. Google Benefits Commercially from Weaker Copyright Protection.
Amici, as creators in the digital age, are largely beholden to the whims of distributors. As romantic the notion is of solitary artists laboring over their works, the fact remains that they will ultimately need to distribute their creative expression. That means going
through Google far more often than not.
Artists like Amici have a tense relationship with Google and its subsidiaries. On the one hand, Google controls access to the market directly or indirectly. On the other hand, Google has consistently abused or outright ignored copyright when it comes to
interactions with creators and their intellectual property.
For example, when YouTube rolled out its subscription service, it reportedly warned independent artists and labels that if they refused YouTube’s licensing terms, their music would be blocked on YouTube’s free service, and YouTube would keep any advertising revenue. Ben Sisario, Independent Music Labels Are in a Battle with YouTube, N.Y. Times
(May 24, 2014) https://www.nytimes.com/2014/05/24/business/media/independent-music-labels-are-in-abattle-with-youtube.html.
In Amici’s experience, Google has a long history of leveraging copyright exceptions for its enormous profit at creators’ expense. Through YouTube, Google profits directly from verbatim copies of Amici’s own works. These copies are often unauthorized, unlicensed, and severely undermonetized. See Jonathan Taplin, Do You Love Music? Silicon Valley Doesn’t, L.A. Times (May 20, 2016).
Google is able to artificially lower the floor for the market for music and other copyrighted works by strategically leveraging a variety of copyright exceptions and loopholes across all of its platforms, particularly YouTube and search.
As discussed above, in order to maximize user engagement with its ads, Google needs a constant influx of creative content. Copyright is treated as an imposition, and Google avoids liability through an abuse of exceptions such as the safe harbor provisions
in the Digital Millennium Copyright Act. See 17 U.S.C. § 512(a)–(d). Google frequently argues that these provisions immunize Google from liability for infringing content, while also making it very easy for Google to restore content with the check of a box.
Google has cobbled together a system of copyright “strikes” based on DMCA notices received from copyright owners against infringing YouTube channels. With sufficient strikes, YouTube blocks public access to the channel. The channel operator, however, can easily restore content by filing a counternotification with YouTube often attesting without firm legal grounds to a good faith belief that their unauthorized use of the material is non-infringing.
Such an assertion frequently mimics Google’s general assertions that the fair use doctrine is malleable enough to accommodate any use no matter how damaging, non-transformative, commercially based or unnecessarily broad. See 17 U.S.C. § 512(g)(3)(C).
Assuming the copyright owner does not seek relief in court—and very few do because of the prohibitive costs and time required—then YouTube restores the content, and Google has another video to monetize.
Thus, assertions of fair use (real or imagined) play a critical role in this scheme, and therefore ultimately Google’s advertising inventory. YouTube’s counternotification
webform, in fact, arguably encourages a channel operator to claim a good-faith belief that its infringing video was fair use under the broadest of circumstances. See Lenz v. Universal Music Corp., 801 F.3d 1126 (9th Cir. 2015).
These channel operators are rarely represented by counsel, meaning their claims of fair use are more folk wisdom and internet legend than law. Five-time Grammy Award winner and independent composer and band leader Maria Schneider gave an example of this culture in comments to the Copyright Office:
“As just one small example, just put in the YouTube “search” bar the phrases “fair use” and “full CD.” There are literally countless whole albums digitally uploaded by users who state that it is “fair use” (which it obviously isn’t).
YouTube knows there is infringement of epic proportions broadly across its platform, and . . .certainly makes it possible, and easier, for infringement to occur.”
Coupled with its porous repeat infringer policy, YouTube has leveraged counternotifications into a broad-based fair use business strategy—truly an attempt to fashion its non-existent “fair use industries” entirely out of whole cloth.
Google overamplifies fair use in other ways. For example, since 2015, YouTube has sponsored an initiative to subsidize legal fees for certain fair use cases that it decides are “some of the best examples of fair use on YouTube by agreeing to defend them in
court if necessary.”34 YouTube announced that it intended to “indemnify creators whose fair use videos have been subject to takedown notices for up to $1 million of legal costs in the event the takedown results in a lawsuit for copyright infringement.”
Google tells us “[they] believe even the small number of videos [Google] are able to protect will make a positive impact on the entire YouTube ecosystem, ensuring
YouTube remains a place where creativity and expression can be rewarded.”
The promise of Google’s million-dollar fair use indemnity promotion effectively provides a faux license against copyright liability without the consent of the copyright owner, and purports to protect YouTube partners for fair use cases that Google judges worthy, i.e., cases that promote Google’s private interests in protecting and expanding YouTube’s advertising inventory. It is unclear which, if any, cases Google or YouTube have taken on under this indemnity or what the criteria would be because Google does not disclose
when or if they get involved. One can easily discern through market behavior, however, that the threat alone more than satisfies Google’s imputed aims to dissuade creators from even attempting to enforce their rights.










You must be logged in to post a comment.